- Home
- Windows Server
- Virtualization
- Improvements in recovery history
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Hyper-V replica has always had the capability to maintain multiple recovery points. In this blog post we’ll delve into “undo logs” – a brand new way for storing recovery points introduced in Windows Server 2012 R2 and how it benefits Hyper-V Replica customers.
Snapshot based recovery history
In Windows Server 2012, we supported recovery history by storing one recovery snapshotsfor each of the configured number of recovery points. Recovery snapshots are meant to provide a fast and easy way to revert a virtual disk to a previous state. Their use allowed for convenient fail-over to any saved recovery point.
The screenshot below shows recovery snapshots on a replica VM with recovery points:
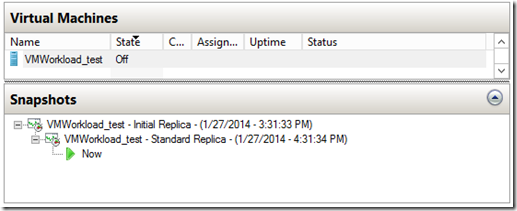
However, due to the way recovery snapshots work, there are some inherent tradeoffs in using them for recovery history. They are:
1. Increased IOPS on the recovery side during normal replication : This effect is more evident when a snapshot is created and tapers off over time. This manifests because any write to a new block that isn’t present in a recovery snapshot results in the allocation and zero-filling of a new block before the write succeeds. On an average this can result in IOPS impact of 4x to 6x where x is the number of write IOs on the primary VM.
2. Data corruption in any of the recovery snapshots impacts failovers to any of later recovery points.
Architectural improvements to recovery history were further informed by our observation that more than 90% of times, customers chose to failover to the latest point; and that when customers did choose a point other than the latest, it was far more likely to be one of the newer points rather than the older points.
Making it better with undo-logs
The undo-log architecture makes use of the efficient change tracking and logging system that is at the core of Hyper-V Replica. The fundamental idea of undo-logs is to save data that is going to be overwritten by the application of a change log into an undo log file. Hence, with the application of undo-log, changes made to a virtual disk can be reverted. One undo-log corresponds to each of the configured recovery points.
Thus, in the undo-log architecture, the data in the replica VHDs is always at the latest state. Failing over to an older point requires application of corresponding undo logs. However, the most favored scenario of failing over to the latest recovery point is made extremely efficient. In fact, there is over 100% improvement in IOPS usage on the recovery side with undo-log approach as opposed to recovery snapshot based approach! Furthermore, should there be any corruption in data in any undo logs, failover to older recovery points is impacted while leaving all the newer recovery points accessible.
|
|
Key changes
Some of the key changes due to the introduction of undo-logs are:
|
Scenario |
Windows Server 2012 |
Windows server 2012 R2 |
|
IOPS impact of enabling recovery history on the replica server |
At an average 4x to 6x. |
At an average 2x to 3x. |
|
Storage required on enabling recovery history |
~10% of the base disk for every recovery point. |
Dependent on the actual churn in the VM. |
|
Supports inter-op with storage migration? |
Yes. |
Yes. |
|
Supports inter-op with live migration? |
Yes. |
Yes. |
|
Supports inter-op with import/export of a VM? |
Yes, recovery points (snapshots) can be exported/imported. |
No, recovery points (undo logs) cannot be exported/imported. |
|
Impact of disk resize |
Disk resize is not advisable when snapshots are present. |
If the disk is expanded, undo-logs continue to provide recovery history. If the disk is contracted, failover to point older than when the disk was resized is not supported. |
|
Time taken to initiate failover to the latest point (Excluding operating system boot time) |
Near instantaneous. |
Near instantaneous. |
|
Time taken to initiate failover to the oldest point (Excluding operating system boot time) |
Near instantaneous. |
Dependent on the actual changes that need to be undone. |
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.