First published on MSDN on Aug 23, 2017
A guest post by Chih Han Chen , Microsoft Student Partner from Imperial College London.

I am currently a second year PhD student at Imperial College London. My research is mainly on expert systems and artificial intelligence for personalized decision based on genetics. I am interested in the application of informatics, big data, machine learning, data value chain and business modelling.
My LinkedIn profile link .
My GitHub for this project .
Overview of this blog
In this blog, I will first briefly introduce what is deep learning and CNTK, provide you some links to the method of installation, then we will dive straight into building a deep neural network on a Natural Language Processing(NLP) task. Furthermore, we will evaluate our model and observe the outputs. Finally, I will summarize with potential extension for anyone who wants to get deeper towards the field.
Introduction
The rise of big data is due to our increased ability to deal with higher volume, velocity and variety of data. Thanks to the recent advancement of available sizes and processing speed of hardware, the higher efficiency of software and the better compatibility of firmware, the research of data and computer science have reached a new era. These research areas cover many fields, such as speech recognition, computer vision, and natural language processing. Deep learning, an extension of artificial neural networks, is coming to play a key role in providing big data predictive analytics solutions, because of its state-of-art performance. The easiest way of making examples would be through the following video, there are good applications of deep learning, such as Microsoft Image understanding project and etc.

I wish you are already excited to dive into the field of machine learning. Well, this blog is not about teaching you the concept of deep learning but to guide you to build your first deep learning neural network. After all there is no better ways of learning by doing. If you are interested knowing more, there are some video links in the Resource video section.
What is CNTK?
Microsoft Cognitive Toolkit, also known as CNTK, is a deep learning framework developed by Microsoft Research. CNTK describes neural networks with composing simple building blocks, which later transformed into complex computational networks to achieve complex deep models with state of art performances. The Microsoft’s internal team is using the exact same tool as the one that open sourced to the public. In 2016, they have posted the below video to introduce this toolkit. So far, CNTK supports only for Windows and Linux users. we can call the library of CNTK from Python, C++ and .NET.
Some more introduction to CNTK can be found on CNTK blog and CNTK tutorial .
What is the NLP task for this blog?
Have you ever been bothered by Spam messages or Emails, or at least heard someone complaining about it? Today we are going to build a deep neural network that detect these Spams. First, let me introduce you an open source dataset: UCI SMS Spam collection Data set . This dataset contains 5,574 messages with labels describing if the message is a spam or not. You can download the data set from the link , or simple copy and paste the codes that I will show later in this blog to automatically download it from Python. Examples of the dataset:
Installation guide
Before we jump start with the coding, let’s set your environment up.
Key things to be installed:
For python installation, check out the Reference for Windows , Reference for Linux .
Or you can install the Data Science Virtual Machine From Microsoft which has all these tools including CNTK preinstalled
All the above tools and services are preinstalled on the Microsoft Data Science VM on Windows 2012, 2016, CentOS or Ubuntu
Learn more about the DSVM Webinar Link: https://info.microsoft.com/data-science-virtual-machine.html
More Product Information: Data Science Virtual Machine Landing Page
Community Forum: DSVM Forum Page
For the openmpi-bin and CNTK, if you are using Linux you can follow either my GitHub guide or the official guide . If you are using windows please follow the official guide .
For other packages, check out and install from links: ‘ matplotlib ’, ‘ numpy link1 ’, ‘ numpy build from source ’. Furthermore, some libraries such as ‘sys’, ‘os’, ‘__future__’, ‘urllib’, ‘zipfile’, ‘csv’, ‘re’ are assumed to be built in.
Let’s get started
If you want to see the result without understanding the codes in detail, you can simple copy the codes/file from my GitHub SpamDetectorFCDNN.py . and type in the terminal:
Alternatively, open a terminal, start python and follow the step by step instruction below with detail explanation of each sections.
How to fit the data with Deep Neural Network(DNN)?
Before we build and train the neural network, the data is required to be transformed into the correct format, so the data can be fit to the input of DNN.
All source code is at https://github.com/ICLMicrosoftProject
Let us get straight into the codes.
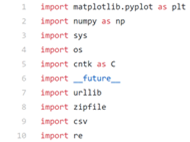
First, we import all the required libraries.
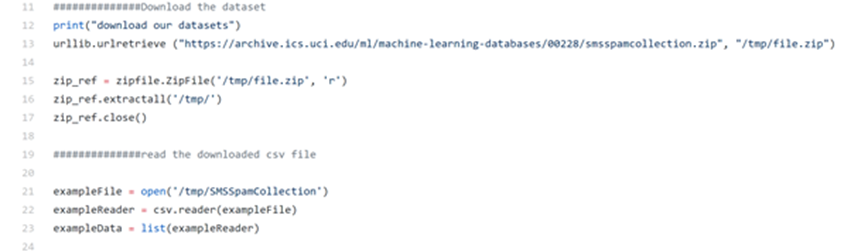
Then we download and unzip the data.
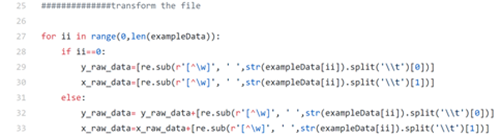
And we load the data with the above codes.
After the above steps, we now have our input text data(x_raw_data) and labels(y_raw_data). Let’s have a quick look of one set of the data from our terminal:
In order to simplify our task, let’s remove all symbols and numbers, convert all letters into lower cases and tokenize the words (cut the sentence string into word by word array) with the following function:
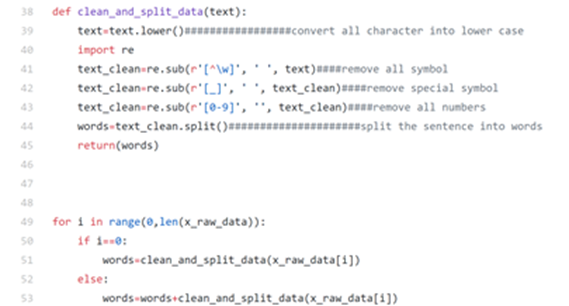
Let’s have a quick look from the terminal:

From the terminal, we can observe the first ten words, additionally the total number of words of our whole dataset and the number is 88,358.
Next we create an id with vector for each unique word with the following codes:
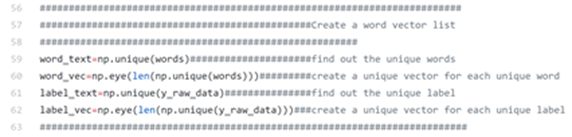
From the terminal:
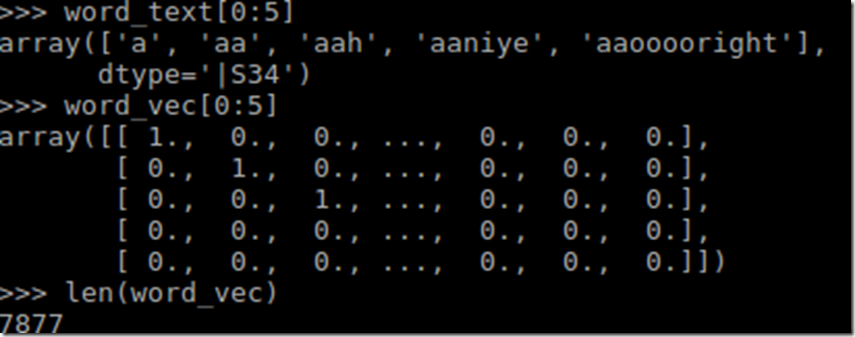
We have sorted the words in order, for example, the first word is ‘a’ and the corresponding id vector is [1, 0, 0…]. We have also found out that there are only 7,877 unique words out of the total 88,358 words. We have also converted our output labels into vectors, as shown below:
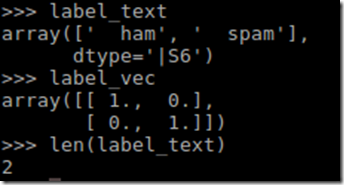
Since there are only two labels, we only have two unique id vectors.
At this stage, we have obtained a look up list to take record of each unique word appears in each sentence. We can execute the following codes to perform a look up of the id vector list and sum the ‘word vectors’, which we call the output as ‘sentence vector’.
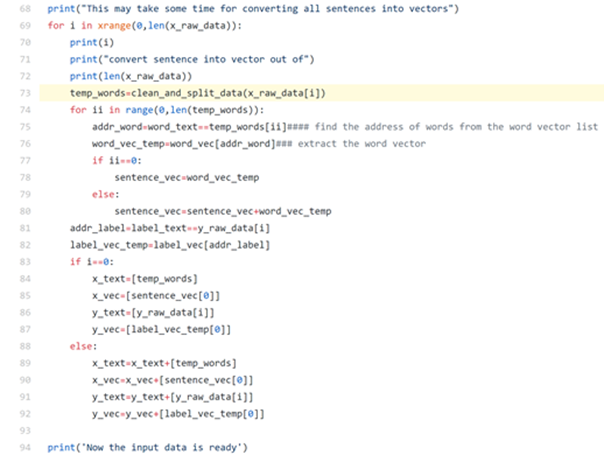
See the examples of the outputs below:
After performing the above codes, we have converted all sentences from the 5,574 messages into 5,574 vectors which record the existence of the unique words in the sentences. And we also have applied the similar method on to the label data and obtain 5,574 label vectors. Let’s take a look at one sentence example from terminal:

In this sentence, there are six unique words therefore there are six ‘1’ in the sentence vector (when you sum them it’s a ‘6’). Note that the total length of the vector is equal to the number of unique words: 7877.
We also split the data into training and testing sets for the later evaluation.
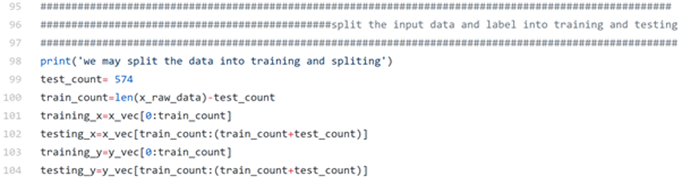
In this case, we split the data into 574 testing sets and 5,000 training sets. (you can change the number as you wish)
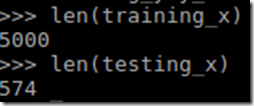
Finally, we place every 50 training data sets into one batch for the purpose of faster training.
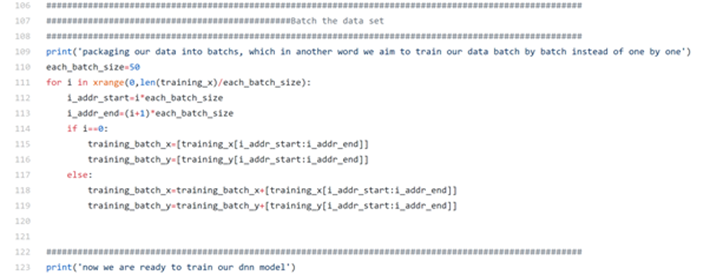
As you can see from the terminal below, we have 100 batches of training data sets, each batch contains 50 data, while each data vector has the length of 7,877(sentence vector = number of unique words)
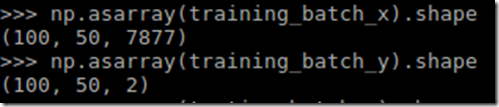
The output label vector is with the length 2 since we only want to know if the answer is a ‘Spam’ or ‘not a Spam (ham)’.
Build the DNN architecture with CNTK
Now we have our data ready, the next big thing is to build our model architecture.
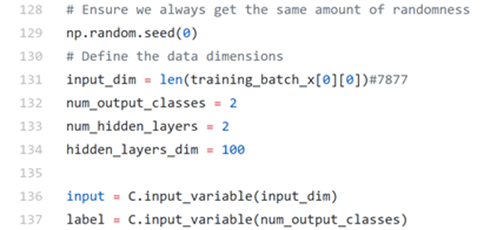
In the above codes, we define our input dimension as the length of sentence vector 7,877 (input a message) and output classes as 2 (‘Spam’ or ‘Not a Spam’). We also define the number of hidden layer as 2 while each layer is with 100 neurons. It is important that we express the input and label as the variable of the CNTK (see the last two lines above). To help you understand the model’s architecture and dimensions, please refer to the graph shown below.
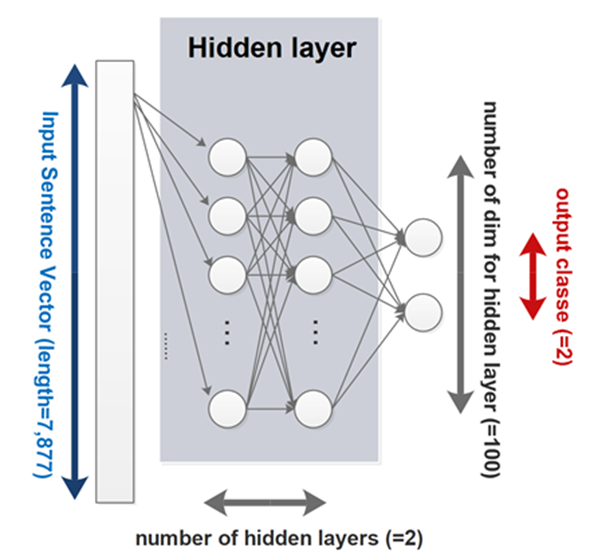
Before we actually create our model graph, let’s define a few functions first.

As we know it is quite common to express the neural network as:

where represents the weight of each input data.
Therefore we first define the linear_layer function as:
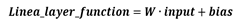
And the linear layer function is wrapped up by the activation function (or nonlinearity), defined as the dense_layer function, which now represents the complete function of a single layer neuron:
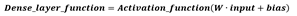
The third function ‘fully_connected_classifier_net’ duplicates the single layer neuron to build a multi-layer model.
For the ease of understanding the structures of each function, I have created a graph to help:
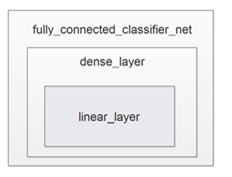
After we defined the necessary functions, we are now ready to create the classifier net with the following codes:

In this work, we use the defined sizes of each parameter in the above sections and define the activation function as sigmoid (you can replace the sigmoid function with other functions).
How to train the DNN with CNTK?
After we successfully create our DNN structure, the next step is to define the training method.

In the above two lines, we build the structure for comparing the model prediction and desired label using CNTK library. Loss is measured by softmax function with cross entropy and error is measured by the classification error function.

The learning rate, defined as 0.5, is wrapped as the learning rate schedule. Since we feed our model with batches, the description of minibatch is also included.

Before we launch our training, we connect our learner ‘sgd’ to the model parameters and learning schedules. Note that you can change the learner based on your needs. Finally, we can compete the trainer with the model z, defined loss, error and the learner.
Now, we launch our training with the following codes:

The training procedure is executed with two ‘for’ loops, where the inner loop ‘i’ represents training the model batch by batch. When we finish training the model with all batches, we start from the beginning with the outer loop ’train_times’. In each training loop, the actual data training batch is loaded to the trainer as features (input) and labels (output). The model parameter is optimized bit by bit based on our pre-defined trainer. Moreover, we are also taking records of the loss and error for each loop.

The records are used to virtualize the training progress, as shown in the plot below:
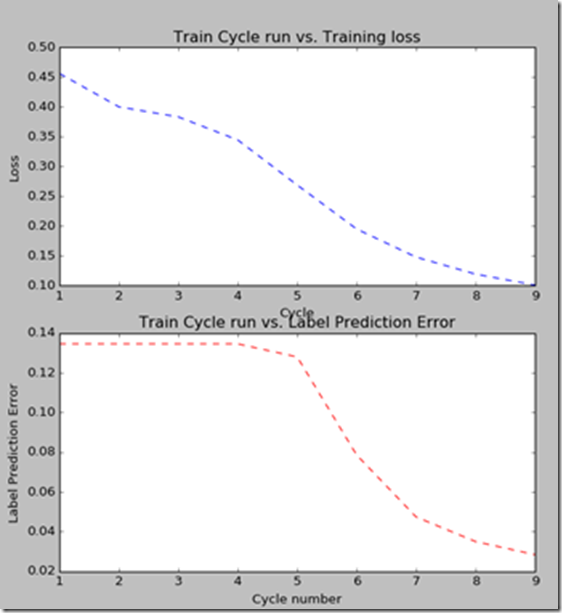
The X-axis represents the number of the training cycle while the Y-axis represents the losses in the first image and errors in the second image. The detail explanation of the loss and error can be found at the official site here .
How to evaluate the model?
In the previous sections, we have learnt how to train the model using the training data sets. Testing data sets are not involved during the training procedures. Therefore our CNTK model should not have a clue but to use the best of its knowledge to perform its function and show us its capability on predicting the testing labels. In this section, we will evaluate the performance of our model.

We connect our trained model ‘z’ to a softmax layer and evaluate the output based on the input features. The input features are stored in ‘testing_x’, consisting of the text of the messages. Let’s take a look at the predicted label based on our testing data sets from our model and the corresponding answer.
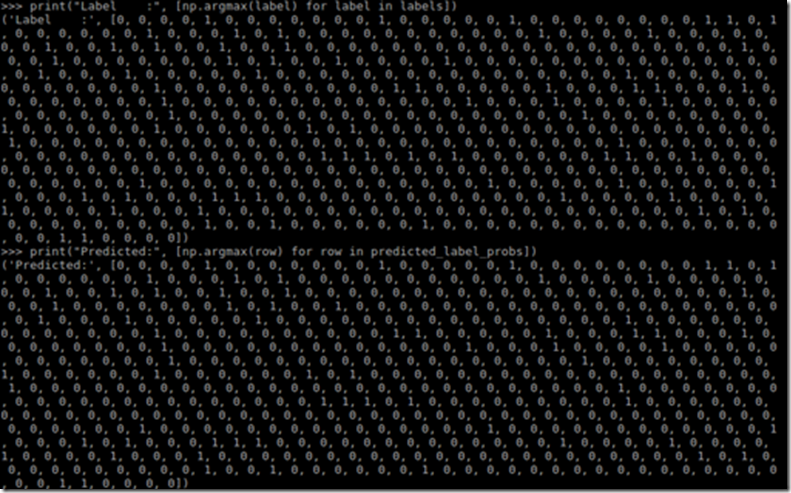
There are 574 outputs of ‘0’ and ‘1’ which are the predictions of ‘ham’ or ‘Spam’. However, it is difficult to manually validate them. Therefore, we use the following codes to compare the results:

After running the above codes we get the results of accuracy:
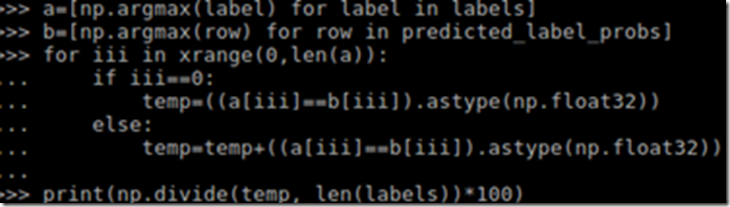

We define the accuracy as the number of correct prediction divided by the total number of labels. We achieve an accuracy of 97.9094076655 %, which is brilliant!
Now you can try to change the number of train_times and see the variations of the accuracy.
Summary:
In this blog, we present a step-by-step guide of building a DNN with CNTK on a simple Natural Language Processing task. We covered the step of data collection, data transformation, word vectorization and data loading. The training procedures and evaluations are performed to show good results.
Congratulation! Now you are part of our A.I. world.
Now, what’s next?
Take a look at some extensions:
For the data, take a look of MINST to have feeling on DNN for computer vision, here .
From the model structures take a look at convolutional neural network and recurrent neural network such as LSTM
Resources :
[1] https://github.com/Microsoft/CNTK
[2] https://docs.microsoft.com/en-us/cognitive-toolkit/Setup-CNTK-on-your-machine
[3] https://blogs.msdn.microsoft.com/uk_faculty_connection/?s=CNTK
[4] Project Source code https://github.com/ICLMicrosoftProject
Some videos:
What is deep learning? https://www.youtube.com/watch?v=O8vlHOKTepQ
A lecture of neural network https://www.youtube.com/watch?v=uXt8qF2Zzfo
A lecture of deep neural networks https://www.youtube.com/watch?v=VrMHA3yX_QI
A guest post by Chih Han Chen , Microsoft Student Partner from Imperial College London.
I am currently a second year PhD student at Imperial College London. My research is mainly on expert systems and artificial intelligence for personalized decision based on genetics. I am interested in the application of informatics, big data, machine learning, data value chain and business modelling.
My LinkedIn profile link .
My GitHub for this project .
Overview of this blog
In this blog, I will first briefly introduce what is deep learning and CNTK, provide you some links to the method of installation, then we will dive straight into building a deep neural network on a Natural Language Processing(NLP) task. Furthermore, we will evaluate our model and observe the outputs. Finally, I will summarize with potential extension for anyone who wants to get deeper towards the field.
Introduction
The rise of big data is due to our increased ability to deal with higher volume, velocity and variety of data. Thanks to the recent advancement of available sizes and processing speed of hardware, the higher efficiency of software and the better compatibility of firmware, the research of data and computer science have reached a new era. These research areas cover many fields, such as speech recognition, computer vision, and natural language processing. Deep learning, an extension of artificial neural networks, is coming to play a key role in providing big data predictive analytics solutions, because of its state-of-art performance. The easiest way of making examples would be through the following video, there are good applications of deep learning, such as Microsoft Image understanding project and etc.
I wish you are already excited to dive into the field of machine learning. Well, this blog is not about teaching you the concept of deep learning but to guide you to build your first deep learning neural network. After all there is no better ways of learning by doing. If you are interested knowing more, there are some video links in the Resource video section.
What is CNTK?
Microsoft Cognitive Toolkit, also known as CNTK, is a deep learning framework developed by Microsoft Research. CNTK describes neural networks with composing simple building blocks, which later transformed into complex computational networks to achieve complex deep models with state of art performances. The Microsoft’s internal team is using the exact same tool as the one that open sourced to the public. In 2016, they have posted the below video to introduce this toolkit. So far, CNTK supports only for Windows and Linux users. we can call the library of CNTK from Python, C++ and .NET.
Some more introduction to CNTK can be found on CNTK blog and CNTK tutorial .
What is the NLP task for this blog?
Have you ever been bothered by Spam messages or Emails, or at least heard someone complaining about it? Today we are going to build a deep neural network that detect these Spams. First, let me introduce you an open source dataset: UCI SMS Spam collection Data set . This dataset contains 5,574 messages with labels describing if the message is a spam or not. You can download the data set from the link , or simple copy and paste the codes that I will show later in this blog to automatically download it from Python. Examples of the dataset:
| label | text |
| ham | Siva is in hostel aha:-. |
| spam | Sunshine Quiz! Win a super Sony DVD recorder if you canname the capital of Australia? Text MQUIZ to 82277. B |
| ham | What you doing? how are you? |
Installation guide
Before we jump start with the coding, let’s set your environment up.
Key things to be installed:
- Python
- openmpi-bin (for CNTK to work with your machine)
- CNTK
- Other packages (for this task)
For python installation, check out the Reference for Windows , Reference for Linux .
Or you can install the Data Science Virtual Machine From Microsoft which has all these tools including CNTK preinstalled
All the above tools and services are preinstalled on the Microsoft Data Science VM on Windows 2012, 2016, CentOS or Ubuntu
Learn more about the DSVM Webinar Link: https://info.microsoft.com/data-science-virtual-machine.html
More Product Information: Data Science Virtual Machine Landing Page
Community Forum: DSVM Forum Page
For the openmpi-bin and CNTK, if you are using Linux you can follow either my GitHub guide or the official guide . If you are using windows please follow the official guide .
For other packages, check out and install from links: ‘ matplotlib ’, ‘ numpy link1 ’, ‘ numpy build from source ’. Furthermore, some libraries such as ‘sys’, ‘os’, ‘__future__’, ‘urllib’, ‘zipfile’, ‘csv’, ‘re’ are assumed to be built in.
Let’s get started
If you want to see the result without understanding the codes in detail, you can simple copy the codes/file from my GitHub SpamDetectorFCDNN.py . and type in the terminal:
Alternatively, open a terminal, start python and follow the step by step instruction below with detail explanation of each sections.
How to fit the data with Deep Neural Network(DNN)?
Before we build and train the neural network, the data is required to be transformed into the correct format, so the data can be fit to the input of DNN.
All source code is at https://github.com/ICLMicrosoftProject
Let us get straight into the codes.
First, we import all the required libraries.
Then we download and unzip the data.
And we load the data with the above codes.
After the above steps, we now have our input text data(x_raw_data) and labels(y_raw_data). Let’s have a quick look of one set of the data from our terminal:
In order to simplify our task, let’s remove all symbols and numbers, convert all letters into lower cases and tokenize the words (cut the sentence string into word by word array) with the following function:
Let’s have a quick look from the terminal:
From the terminal, we can observe the first ten words, additionally the total number of words of our whole dataset and the number is 88,358.
Next we create an id with vector for each unique word with the following codes:
From the terminal:
We have sorted the words in order, for example, the first word is ‘a’ and the corresponding id vector is [1, 0, 0…]. We have also found out that there are only 7,877 unique words out of the total 88,358 words. We have also converted our output labels into vectors, as shown below:
Since there are only two labels, we only have two unique id vectors.
At this stage, we have obtained a look up list to take record of each unique word appears in each sentence. We can execute the following codes to perform a look up of the id vector list and sum the ‘word vectors’, which we call the output as ‘sentence vector’.
See the examples of the outputs below:
| Type | Text | Id vector | Note |
| Word 1. | i | [1, 0, 0, 0, 0, …] | |
| Word 2. | love | [0, 0, 1, 0, 0 …] | |
| Word 3. | nlp | [0, 0, 0, 1, 0 …] | |
| Sentence | i love nlp | [1, 0, 1, 1, 0 …] | Sentence vector = sum(all Words vectors) |
After performing the above codes, we have converted all sentences from the 5,574 messages into 5,574 vectors which record the existence of the unique words in the sentences. And we also have applied the similar method on to the label data and obtain 5,574 label vectors. Let’s take a look at one sentence example from terminal:
In this sentence, there are six unique words therefore there are six ‘1’ in the sentence vector (when you sum them it’s a ‘6’). Note that the total length of the vector is equal to the number of unique words: 7877.
We also split the data into training and testing sets for the later evaluation.
In this case, we split the data into 574 testing sets and 5,000 training sets. (you can change the number as you wish)
Finally, we place every 50 training data sets into one batch for the purpose of faster training.
As you can see from the terminal below, we have 100 batches of training data sets, each batch contains 50 data, while each data vector has the length of 7,877(sentence vector = number of unique words)
The output label vector is with the length 2 since we only want to know if the answer is a ‘Spam’ or ‘not a Spam (ham)’.
Build the DNN architecture with CNTK
Now we have our data ready, the next big thing is to build our model architecture.
In the above codes, we define our input dimension as the length of sentence vector 7,877 (input a message) and output classes as 2 (‘Spam’ or ‘Not a Spam’). We also define the number of hidden layer as 2 while each layer is with 100 neurons. It is important that we express the input and label as the variable of the CNTK (see the last two lines above). To help you understand the model’s architecture and dimensions, please refer to the graph shown below.
Before we actually create our model graph, let’s define a few functions first.
As we know it is quite common to express the neural network as:
where represents the weight of each input data.
Therefore we first define the linear_layer function as:
And the linear layer function is wrapped up by the activation function (or nonlinearity), defined as the dense_layer function, which now represents the complete function of a single layer neuron:
The third function ‘fully_connected_classifier_net’ duplicates the single layer neuron to build a multi-layer model.
For the ease of understanding the structures of each function, I have created a graph to help:
After we defined the necessary functions, we are now ready to create the classifier net with the following codes:
In this work, we use the defined sizes of each parameter in the above sections and define the activation function as sigmoid (you can replace the sigmoid function with other functions).
How to train the DNN with CNTK?
After we successfully create our DNN structure, the next step is to define the training method.
In the above two lines, we build the structure for comparing the model prediction and desired label using CNTK library. Loss is measured by softmax function with cross entropy and error is measured by the classification error function.
The learning rate, defined as 0.5, is wrapped as the learning rate schedule. Since we feed our model with batches, the description of minibatch is also included.
Before we launch our training, we connect our learner ‘sgd’ to the model parameters and learning schedules. Note that you can change the learner based on your needs. Finally, we can compete the trainer with the model z, defined loss, error and the learner.
Now, we launch our training with the following codes:
The training procedure is executed with two ‘for’ loops, where the inner loop ‘i’ represents training the model batch by batch. When we finish training the model with all batches, we start from the beginning with the outer loop ’train_times’. In each training loop, the actual data training batch is loaded to the trainer as features (input) and labels (output). The model parameter is optimized bit by bit based on our pre-defined trainer. Moreover, we are also taking records of the loss and error for each loop.
The records are used to virtualize the training progress, as shown in the plot below:
The X-axis represents the number of the training cycle while the Y-axis represents the losses in the first image and errors in the second image. The detail explanation of the loss and error can be found at the official site here .
How to evaluate the model?
In the previous sections, we have learnt how to train the model using the training data sets. Testing data sets are not involved during the training procedures. Therefore our CNTK model should not have a clue but to use the best of its knowledge to perform its function and show us its capability on predicting the testing labels. In this section, we will evaluate the performance of our model.
We connect our trained model ‘z’ to a softmax layer and evaluate the output based on the input features. The input features are stored in ‘testing_x’, consisting of the text of the messages. Let’s take a look at the predicted label based on our testing data sets from our model and the corresponding answer.
There are 574 outputs of ‘0’ and ‘1’ which are the predictions of ‘ham’ or ‘Spam’. However, it is difficult to manually validate them. Therefore, we use the following codes to compare the results:
After running the above codes we get the results of accuracy:
We define the accuracy as the number of correct prediction divided by the total number of labels. We achieve an accuracy of 97.9094076655 %, which is brilliant!
Now you can try to change the number of train_times and see the variations of the accuracy.
Summary:
In this blog, we present a step-by-step guide of building a DNN with CNTK on a simple Natural Language Processing task. We covered the step of data collection, data transformation, word vectorization and data loading. The training procedures and evaluations are performed to show good results.
Congratulation! Now you are part of our A.I. world.
Now, what’s next?
Take a look at some extensions:
For the data, take a look of MINST to have feeling on DNN for computer vision, here .
From the model structures take a look at convolutional neural network and recurrent neural network such as LSTM
Resources :
[1] https://github.com/Microsoft/CNTK
[2] https://docs.microsoft.com/en-us/cognitive-toolkit/Setup-CNTK-on-your-machine
[3] https://blogs.msdn.microsoft.com/uk_faculty_connection/?s=CNTK
[4] Project Source code https://github.com/ICLMicrosoftProject
Some videos:
What is deep learning? https://www.youtube.com/watch?v=O8vlHOKTepQ
A lecture of neural network https://www.youtube.com/watch?v=uXt8qF2Zzfo
A lecture of deep neural networks https://www.youtube.com/watch?v=VrMHA3yX_QI
Updated Mar 21, 2019
Version 2.0Lee_Stott Microsoft
Microsoft
MicrosoftJoined September 25, 2018
Educator Developer Blog
Follow this blog board to get notified when there's new activity