Blog written by Sripresanna in the Storage, Network & Print Team
Cluster aggregated view for Windows Storage Provider
In this blog, I’d like to explain about the new cluster aggregated view feature that is part of the Storage Management on Windows Server 2012 R2. For a quick overview of the Storage Management at Microsoft, refer to the Windows 2012 R2 Storage (scroll to SM API) and Getting Started with SMI-S
In a cluster environment, there are two types of storage subsystem:
1. Standalone subsystem: Storage resources that are directly connected to the storage node.
2. Cluster subsystem: Storage resources that are either clustered or clusterable.
a) Clustered - Storage resources that are already part of the cluster. IsClustered Property
b) Clusterable – Storage resources that can be potentially added to the cluster. If a storage object is reachable from a cluster node, then that storage object is considered to be clusterable. Disks (even if disks are not fully shared across all cluster nodes) with below bustypes are in the Clusterable category – “iSCSI”, “SAS”, “Fiber Channel”, and potentially “Storage Spaces (if pool is in shared view)”
Challenge: In Windows 2008, the management layer of cluster storage required administrator to do extra task to view all the storage resources. The administrator had to go to each cluster node, enumerate the storage and combine the list to understand what storage is clustered and what is local to the node.
Solution: In Windows 2012 R2, we introduced a feature called cluster aggregated view. With this feature, the Storage Provider performs the above tasks for the administrator and presents a unified view called cluster aggregated view. As a result, the administrator can view both local and cluster subsystem resources and uniquely identify the objects from any cluster nodes without performing any extra task. Thus, saves time and makes the management of storage subsystem easier. This feature is implemented in the Windows storage provider and other SMP providers can chose to do it.
Getting Started Guide : In this part, I’ll walk you step-by-step to illustrate the cluster aggregate feature in Windows Server 2012 R2 and its implications on a Symmetric storage configuration
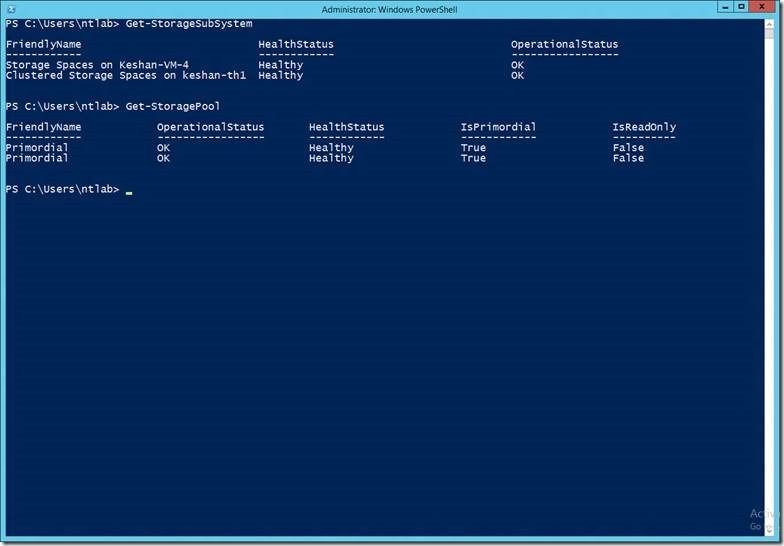
In a symmetric storage configuration, all the cluster capable drives are connected to all the storage nodes. In this example, there are two cluster nodes viz. Keshan-VM-4 and Keshan-VM-7. The below table shows the storage subsystem for both the nodes.
|
Node |
Standalone Subsystem |
Cluster Subsystem |
|
Keshan-VM-4 |
Storage Spaces on Keshan-VM-4 |
Clustered Storage Spaces on keshan-th1 |
|
Keshan-VM-7 |
Storage Spaces on Keshan-VM-7 |
Clustered Storage Spaces on keshan-th1 |


PowerShell snippet showing the Storage Subsystem from node1 and node2
a. Enumerate physical disks in each subsystem
Enumerating physical disks (using Get-PhysicalDisk) shows drives in the standalone subsystem of the current node and the aggregation of drives in the cluster subsystem across all cluster nodes.
Keshan-VM-4 has only the OS disk in its standalone subsystem and Keshan-VM-7 has three. On both nodes the cluster subsystem contains the 10 SAS disks shared between the two cluster nodes.

PowerShell snippet showing the Physical disks in each Storage subsystem on node - Keshan-VM-4

PowerShell snippet showing the Physical disks in each Storage subsystem on node - Keshan-VM-7
b. Creating a Storage pool
In Win8, a pool was created using drives with “CanPool” property of “true”. In R2, this still works for a standalone system containing only one subsystem. On a cluster node, which now has two subsystems, here’s the mechanism to create a pool.
To create a pool in the Standalone subsystem, use the local poolable physical disks. Enumerating the drives using Get-StoragePool shows the pools in the standalone subsystem of the current node and the aggregation of the pools in the cluster subsystem across all cluster nodes. The newly created pool “localpool” is in the local subsystem of the node “Keshan-VM-7”.

“localpool” will not be seen in the pool aggregated view on the other cluster node “Keshan-VM-4”
PowerShell snippet to create a pool on local subsystem of Keshan-VM-4
When the pool is created in the cluster subsystem, it will appear in the pool aggregated view on all of the cluster nodes.

PowerShell snippet to create a pool on local subsystem from node Keshan-VM-4
Few things to note:
- A pool can be created only using drives that belong to the same subsystem
- A pool created on a cluster subsystem is by default clustered (added to the cluster). To disable auto-clustering of a pool, the “EnableAutomaticClustering” flag needs to be set to “false” on the cluster subsystem


From then on, to add the pool to the cluster, the Add-ClusterResource cmdlet should be used.
c. Creating virtual disk

PowerShell snippet to enumerate pool in local Subsystem, create Virtual Disk and enumerate it

PowerShell snippet to enumerate pool in cluster Subsystem, create Virtual Disk and enumerate it
Pool and Space owner nodes
In R2, a new StorageNode object has been introduced to represent a node. This is used in the following scenarios:
- To determine storage topology i.e. connectivity of physical disks and enclosures to cluster nodes
- To find out on which node the pool/Space is Read-Write – pool owner and space owner nodes.
The below output for Get-StorageNode executed from cluster node “Keshan-VM-4” shows the storage nodes in the local and cluster subsystems.

In the cluster, the pool and Space are Read-Write, only on one of the nodes. To get the owner node, use the StorageNode to StoragePool/VirtualDisk association. The below screenshot shows that node “Keshan-VM-4” is the pool owner of the clustered pool “cluspool”. This was run from “Keshan-VM-4”

The below snippet shows that “Keshan-VM-4” is also the Space owner node for “clusVD”.

 Microsoft
Microsoft