First published on MSDN on May 26, 2017
In my previous blog post , I briefly talked about smart transaction log backup, monitoring and diagnostics along with other community driven improvements we released in SQL Server 2017 CTP 2.0. In this blog post we will go deep into a new DMF sys.dm_db_log_stats which we released in SQL Server 2017 CTP 2.1 that will enable DBAs and SQL Server community to build scripts and solutions that performs smart backups, monitoring and diagnostics of transaction log.
Most DBAs today operating their SQL Server database in full recovery model schedule their transaction log backups to recur on a specific time interval for instance, every 15 mins for a highly transactional database to avoid autogrowth of the transaction log files. This works very well assuming transactional activity is consistent or predictable throughout the backup interval, producing transaction log backup files of equal size with no autogrows. In most real-world production environment today, this is not true and pattern of transactional activity seen is similar to the one shown below. In the example shown below, the transactions between 9am – 9:15am are below average which produces a small transaction log backup file at 9:15 am but more importantly doesn't lead to any autogrow. The transaction log activity between 9:15am – 9:30 am is higher than average and may cause all VLFs in transaction log file to be full which cannot be truncated due to pending backup. Thus, it leads to autogrow. Autogrow setting is like auto insurance where you would keep it ON but hope you never use it since it would hurt you over a long run. In this scenario, if you do not have any monitoring in place, you might end up with 1000s of VLFs due to frequent autogrows resulting to space issues, slow recovery, rollback issues, replication latency and cluster failovers with SQL Server resource taking long time to come online.

In sys.dm_db_log_stats , you will find a new column log_since_last_log_backup_mb which can be used in your backup script to trigger a transaction log backup when log generated since last backup exceeds a threshold value. With smart transaction log backup, the transaction log backup size would be consistent and predictable avoiding autogrows from transactional burst activity on the database. The resulting pattern from the transaction log backup would be similar to below.

In sys.dm_db_log_stats , we have exposed couple of columns for VLF monitoring viz total_vlf_count and active_vlfs allowing you to monitor and alert if the total number of VLFs of the transaction log file exceeds a threshold value. Usually when you exceed 100s of VLF or if active_vlfs is approaching closer to total_vlfs, a DBA should be alerted to understand the cause of the transaction log truncation holdup and growth. A DBA can check log_truncation_holdup_reason column to understand the cause of the log truncation holdup and respond to the alert accordingly depending on the reason found. While monitoring your transaction log, total_vlf_count and active_vlfs values can be captured periodically in a scheduled job to report the usage pattern and monitor the overall health of the transaction log.
A healthy VLF usage pattern will look like below. Each time a transaction log backup is completed for full recovery database or checkpoint is completed for simple recovery database, log truncation would occur causing the active_vlfs to drop while total_vlfs remain constant.
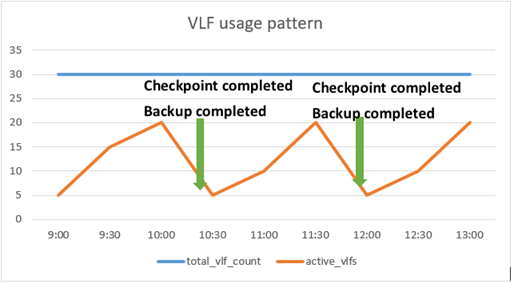
If a log truncation doesn't happen and active_vlfs approaches total_vlfs, it would lead to autogrow causing total_vlfs to increase. Now when the log truncation is unblocked and resumes, the active_vlfs falls back but the total_vlfs holds on to the new value until you shrink your transaction log files. Shrinking your transaction log file often can lead to disk fragmentation and reduce your disk throughput and performance.

Finally, following pattern can be most dangerous and leading indicators of poor health and maintenance of transaction log. It is important to understand the cause of log truncation holdup reason in this case and size the transaction log appropriately to avoid this scenario.
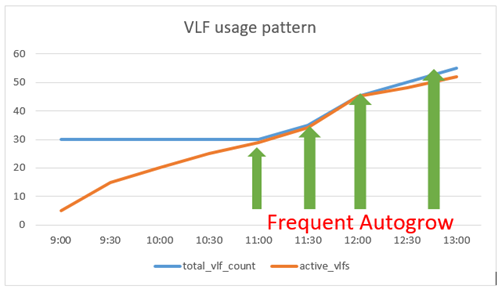
While monitoring transaction logs, one of the most important alerts is when transaction log backup is not completed for more than x hours. Transaction log backup failures can expose you to data loss and lead to log truncation holdup resulting into frequent autogrows. The log_backup_time column in sys.dm_db_log_stats can be used to determine the last transaction log backup and can be used to alert a DBA and trigger a backup in response to the alert. The last log backup time can also be derived from msdb database but one of the advantage of using log_backup_time column in sys.dm_db_log_stats is, it also accounts for the transaction log backup completed on secondary replica if the database is configured in Availability groups. If you are using msdb.dbo.backupset to trigger an alert for delayed or failed transaction log backups, it can lead to false triggers when database state changes in Availability groups as the msdb database is not synchronized.
In sys.dm_db_log_stats, backup_lsn, checkpoint_lsn, recovery_lsn columns are exposed which can be used for troubleshooting and diagnostics. These lsns values can help you visualize a rough sketch of transaction log. Every once in a while, a DBA faces a situation where a user has a long running transaction in killed\rollback state causing blocking issue. In such scenario, a DBA is often in a dilemma to wait or restart the SQL Server instance hoping the universal solution would do the trick. In such scenario, a DBA can look at recovery_vlf_count and log_recovery_size_mb to understand the number of vlfs to recover and log size to recover if the database is restarted. High number of recovery_vlfs and log recovery size can lead to entire database in recovery state for long time if the database is restarted. High values of recovery vlfs and log recovery size can also be used as leading indicators for long failover time in FCI scenarios.
I am sure there are more scenarios where customers and community will find sys.dm_db_log_stats useful to proactively maintain a healthy state of the transaction log and improve the overall availability and predictability of the SQL Server instance.
Parikshit Savjani
Senior PM, SQL Server Tiger Team
Twitter | LinkedIn
Follow us on Twitter: @mssqltiger | Team Blog: Aka.ms/sqlserverteam
In my previous blog post , I briefly talked about smart transaction log backup, monitoring and diagnostics along with other community driven improvements we released in SQL Server 2017 CTP 2.0. In this blog post we will go deep into a new DMF sys.dm_db_log_stats which we released in SQL Server 2017 CTP 2.1 that will enable DBAs and SQL Server community to build scripts and solutions that performs smart backups, monitoring and diagnostics of transaction log.
Smart Transaction Log Backups
Most DBAs today operating their SQL Server database in full recovery model schedule their transaction log backups to recur on a specific time interval for instance, every 15 mins for a highly transactional database to avoid autogrowth of the transaction log files. This works very well assuming transactional activity is consistent or predictable throughout the backup interval, producing transaction log backup files of equal size with no autogrows. In most real-world production environment today, this is not true and pattern of transactional activity seen is similar to the one shown below. In the example shown below, the transactions between 9am – 9:15am are below average which produces a small transaction log backup file at 9:15 am but more importantly doesn't lead to any autogrow. The transaction log activity between 9:15am – 9:30 am is higher than average and may cause all VLFs in transaction log file to be full which cannot be truncated due to pending backup. Thus, it leads to autogrow. Autogrow setting is like auto insurance where you would keep it ON but hope you never use it since it would hurt you over a long run. In this scenario, if you do not have any monitoring in place, you might end up with 1000s of VLFs due to frequent autogrows resulting to space issues, slow recovery, rollback issues, replication latency and cluster failovers with SQL Server resource taking long time to come online.
In sys.dm_db_log_stats , you will find a new column log_since_last_log_backup_mb which can be used in your backup script to trigger a transaction log backup when log generated since last backup exceeds a threshold value. With smart transaction log backup, the transaction log backup size would be consistent and predictable avoiding autogrows from transactional burst activity on the database. The resulting pattern from the transaction log backup would be similar to below.
Smart Transaction Log Monitoring and alerting
Monitoring VLFs
In sys.dm_db_log_stats , we have exposed couple of columns for VLF monitoring viz total_vlf_count and active_vlfs allowing you to monitor and alert if the total number of VLFs of the transaction log file exceeds a threshold value. Usually when you exceed 100s of VLF or if active_vlfs is approaching closer to total_vlfs, a DBA should be alerted to understand the cause of the transaction log truncation holdup and growth. A DBA can check log_truncation_holdup_reason column to understand the cause of the log truncation holdup and respond to the alert accordingly depending on the reason found. While monitoring your transaction log, total_vlf_count and active_vlfs values can be captured periodically in a scheduled job to report the usage pattern and monitor the overall health of the transaction log.
A healthy VLF usage pattern will look like below. Each time a transaction log backup is completed for full recovery database or checkpoint is completed for simple recovery database, log truncation would occur causing the active_vlfs to drop while total_vlfs remain constant.
If a log truncation doesn't happen and active_vlfs approaches total_vlfs, it would lead to autogrow causing total_vlfs to increase. Now when the log truncation is unblocked and resumes, the active_vlfs falls back but the total_vlfs holds on to the new value until you shrink your transaction log files. Shrinking your transaction log file often can lead to disk fragmentation and reduce your disk throughput and performance.
Finally, following pattern can be most dangerous and leading indicators of poor health and maintenance of transaction log. It is important to understand the cause of log truncation holdup reason in this case and size the transaction log appropriately to avoid this scenario.
Monitoring log backup time
While monitoring transaction logs, one of the most important alerts is when transaction log backup is not completed for more than x hours. Transaction log backup failures can expose you to data loss and lead to log truncation holdup resulting into frequent autogrows. The log_backup_time column in sys.dm_db_log_stats can be used to determine the last transaction log backup and can be used to alert a DBA and trigger a backup in response to the alert. The last log backup time can also be derived from msdb database but one of the advantage of using log_backup_time column in sys.dm_db_log_stats is, it also accounts for the transaction log backup completed on secondary replica if the database is configured in Availability groups. If you are using msdb.dbo.backupset to trigger an alert for delayed or failed transaction log backups, it can lead to false triggers when database state changes in Availability groups as the msdb database is not synchronized.
Smart Transaction Log diagnostics
In sys.dm_db_log_stats, backup_lsn, checkpoint_lsn, recovery_lsn columns are exposed which can be used for troubleshooting and diagnostics. These lsns values can help you visualize a rough sketch of transaction log. Every once in a while, a DBA faces a situation where a user has a long running transaction in killed\rollback state causing blocking issue. In such scenario, a DBA is often in a dilemma to wait or restart the SQL Server instance hoping the universal solution would do the trick. In such scenario, a DBA can look at recovery_vlf_count and log_recovery_size_mb to understand the number of vlfs to recover and log size to recover if the database is restarted. High number of recovery_vlfs and log recovery size can lead to entire database in recovery state for long time if the database is restarted. High values of recovery vlfs and log recovery size can also be used as leading indicators for long failover time in FCI scenarios.
I am sure there are more scenarios where customers and community will find sys.dm_db_log_stats useful to proactively maintain a healthy state of the transaction log and improve the overall availability and predictability of the SQL Server instance.
Parikshit Savjani
Senior PM, SQL Server Tiger Team
Twitter | LinkedIn
Follow us on Twitter: @mssqltiger | Team Blog: Aka.ms/sqlserverteam
Updated Mar 23, 2019
Version 2.0ParikshitSavjani
Former Employee
Joined August 23, 2017
SQL Server Blog
Follow this blog board to get notified when there's new activity