In the recent past, we worked on an issue where a number of updates on a replicated article (part of transactional replication) were delivered to the subscriber as a series of DELETEs and INSERTs as opposed to UPDATEs. In this post, I will explain the scenarios under which this situation can occur and what the options are to workaround the situation.
Let us consider a scenario that you are replicating a large table which has a primary key and also a unique non-clustered index. The table and index definitions are provided below.
CREATE TABLE [dbo].[TestReplic](
[id] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[c1] [int] NOT NULL,
[c2] [int] NOT NULL,
[c3] [int] NOT NULL,
CONSTRAINT [PK_TestReplic] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
CREATE UNIQUE NONCLUSTERED INDEX [UX_TestReplic_c1_c2] ON [dbo].[TestReplic]
(
[c1] ASC,
[c2] ASC
)
INCLUDE ([c3]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
When you execute an update on a table which updates one of the included columns in the unique non-clustered index, then SQL Server has the option to one of the following:
a. Perform the update as-is and update the clustered and unique non-clustered in a single operation
b. Perform the update as a Split operation by splitting each UPDATE into a DELETE and an INSERT operation. During such a scenario, you will find a SPLIT operator in the UPDATE plan for the table on the publisher.
There are number of heuristics information that SQL Server evaluates to split an UPDATE into a DELETE and INSERT pair. The decision is based on evaluation of a function which determines which of the above options would be better for performance.
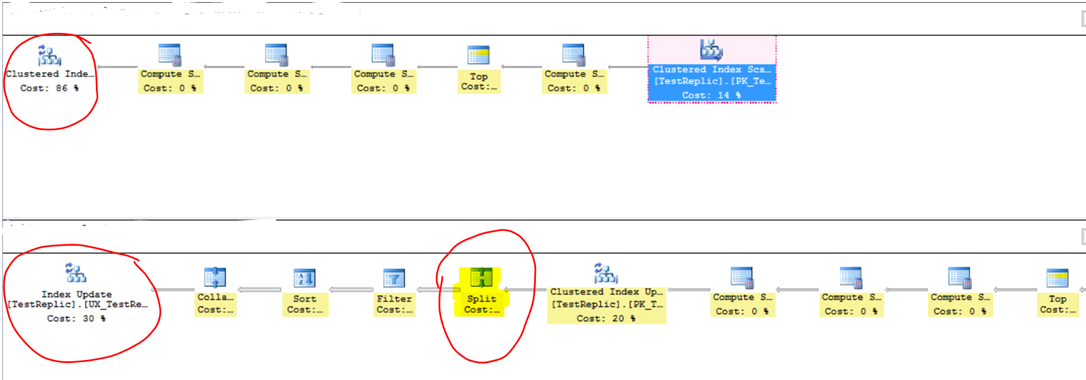
When you compare the query plans for the plan with a single UPDATE and the plan with split DELETE and INSERT statements, you will find that:
a. A single clustered index update performs the update for the non-clustered unique index and the clustered index
b. A SPLIT operator appears in the query plan where the indexes are maintained separately. The first operation performed is a clustered index update for the clustered index and another index update for the unique non-clustered index
The screenshot below illustrates the difference.
If you are tracing the replication statements, you will find that the first case will only show the execution of “ sp_MSupd_dbo<object name> ” for performing the updates. The second case will show “ sp_MSdel_dbo<objectname>” and “ sp_MSins_dbo<objectname> ” for the split update scenario.
Tracing the number of commands delivered in the distribution database for a single update or tracking down the query plans or tracking down the stored procedure executions will give you a hint that you have a SPLIT UPDATE in play.
The next question is how do you prevent this from happening. There are a few options that you can exercise:
a. Enable trace flag 2338 at the query level which will prevent the query optimizer from picking per-index plans because of performance. Example of such an update query is shown below.
UPDATE t
SET t.c3=1
FROM dbo.TestReplic tUPDATE TOP(300) dbo.testreplic
SET c3+=1
WHERE c3 = 0 OPTION (querytraceon 2338 )
WHERE t.c3 = 10000
Note - Executing a query with the QUERYTRACEON option requires membership in the sysadmin fixed server role. Please read this article for details.
b. The per-index plans are generated for index updates when a large number of rows are affected. So another option would be to perform the update in smaller batches.
c. Alternatively, you could create a stored procedure which would perform the UPDATE and then add the stored procedure as a replicated object to your publication. Please read this article for more information on how to publish stored procedure execution.
Wish all of you a Happy New Year in advance from the Tiger team!