First published on MSDN on Jan 31, 2018
JSON support in SQL Server 2016+ and Azure SQL Database enables you to combine relational and NoSQL concepts and easily transform relational to semi-structured data and vice-versa. JSON is not a replacement for the exiting relational models, and there are some specific use cases when you should use JSON in SQL Database. In this post will be described the most common use cases when JSON in SQL Server could be used.
Classic relational databases force you to create highly normalized data models where high-level concepts such as Customer, Order, or Invoice are physically decoupled from their related entities such as Customer emails, Customer phones, Product parts, Order Line Items, Invoice tags, etc. Normalized models require high granularity of entities because they are designed to support a large number of independent transactions that are updating both conceptual entities and their parts at the same time. Breaking conceptual entities into the separate tables enables each transaction to update its own table without affecting others. The drawback of this approach is the fact that you need to get information from different tables to reconstruct one complex entity and its attributes, and also the fact that there is a risk of locks and even deadlocks if a transaction must atomically update several tables.
De-normalized models, on the other hand, merge the dependent entities into the main conceptual entities as cells with serialized collections and other complex objects. This way you need single lookup to retrieve or update the entity and all related data. However, this model is not suitable if you have frequent updates of related data.
The ideal model depends on the nature of your data and workload, so need to consider how the data will be used when you are choosing between normalization and de-normalization.
SQL Server and Azure SQL Database are general-purpose multi-model databases that enable you to combine the classic relational concepts with NoSQL concepts such as JSON, XML, and Graphs. Unlike classic relational and NoSQL database, SQL Database do not force you to choose between these two concepts – it enables you to combine the best characteristics of relational and non-relational models on the different entities in the same database in order to create an optimal data model.
[caption id="attachment_6155" align="alignnone" width="879"]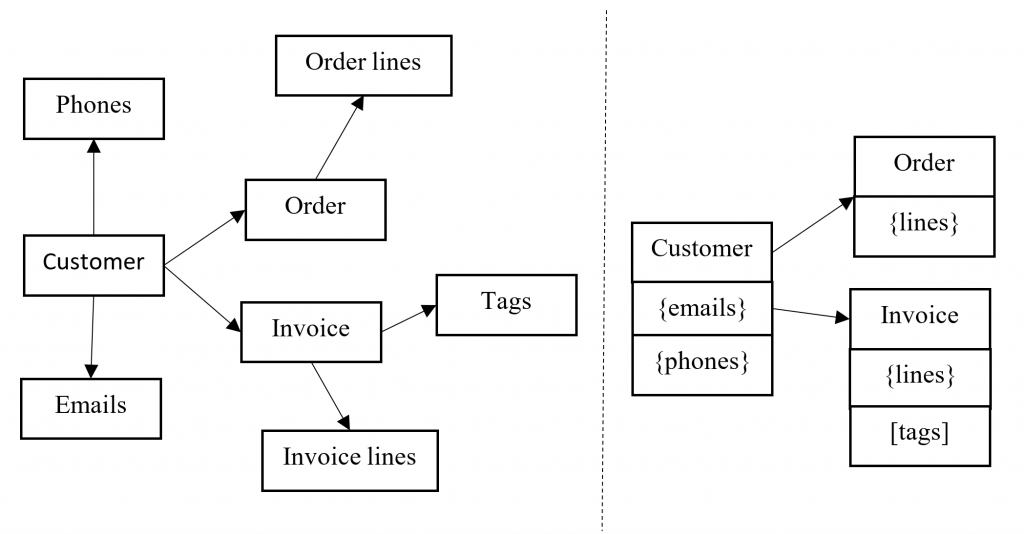 Difference between normalized and de-normalized models[/caption]
Difference between normalized and de-normalized models[/caption]
This way, you can have a set of standard relational tables with foreign keys and referential integrity, and complex data such as lists, arrays, collections, and dictionaries formatted as JSON or XML, spatial data or even graph relationships between the tables. SQL Server and Azure SQL Database enable you to fine tune design of your data model and use the most appropriate data structures depending on your use case.
If you have data models where related data are not frequently updated, you can store related entities in table cells as sub-collection formatted as JSON and combine simplicity of NoSQL design with the power of querying with SQL.
See example of de-normalization in action in this post .
Single-page applications represent the modern architecture for building web applications. They are based on the rich JavaScript application frameworks and libraries, and have a lot of client-side JavaScript code that is executing in the web browsers. Single-page applications communicate with backend systems via HTTP/AJAX requests that retrieve or send JSON messages to some REST APIs, which gets or stores data in the database. One of the main difficulties in web development is transformation of relation data into JSON messages and vice versa. In classic REST API you need to get the data from the database and transform it to JSON message that will be sent to your single-page application.
FOR JSON clause and OPENJSON function enable you to easily transform relational data stored in tables to JSON and to parse JSON text coming from the single-page applications into SQL database. This might be a perfect tool for building REST API for single page apps that communicate with backed system using JSON messages.
With JSON operators and functions, you can easily get the data from SQL tables or create complex reports using T-SQL, format results as JSON text and let REST API to return this text to some client-side app.
OPENJSON function enable you to get the JSON models sent by single-page applications, parse it and store it into a table.
See more details about building REST API for single page applications in this post , and an example that shows how to create REST API back-end to Angular application here .
Product catalog pattern is a common pattern in retail and E-commerce applications where you need to design a data structure that stores various types of products. The products in retail and e-commerce apps might have various properties/attributes. Depending on the type, some products might have dimensions and weight, others color, taste, price, number of doors, CPU, memory, etc. Attributes for this data may vary and can change over time to fit application requirements.
Designing a table that should store diverse types of products might be a challenge in classic relational databases because a large set of variable attributes cannot fit into the classic relational model. Data designers use different database design patterns such as wide sparse table, high normalization, or entity-attribute-value pattern to design variable attributes in a product catalog.
NoSQL databases are also a viable option for storing product catalog data because every product can be serialized as JSON document that contains only the properties that are applicable to the particular product type. However, in this case you need to have small and self-contained application where there are minimal interaction between products and other entities such as orders, customers, suppliers, etc. If these related entities are stored in the relational database, NoSQL is not an option because you have a central part of the domain model (product) disconnected from other entities.
With built-in JSON support, SQL database enables you to store variable attributes in a single cell formatted as JSON documents, like in NoSQL databases. See example of product catalog implementation in this post . The advantage of this approach is that product collections stored in SQL database are still connected to other tables in the database. In addition, you can apply the same indexing strategies on product catalog data formatted as JSON as you do on classic relational columns:
Storing product catalogs in SQL database is preferred model if your product collection is tightly coupled with other entities in the database (for example orders, customers, invoices), because it enables you to query and join your product collection wit any other database entity.
Applications and devices generate large volumes of telemetry data, with information what happened in the app, error details, etc. Data can be formatted as plain text, delimited files (e.g. comma or tab separated values), JSON, etc. If you want to analyze plain text logs you might need to deal with complex parsing and regular expressions. CSV or TSV is easy for parsing; however, they require a fixed set of columns. JSON is in many cases chosen as a format for logs with trade-off between availability of parsing tools and flexibility of structure.
Telemetry data ends-up into log files that are stored on file systems, Azure Blob Storage, Hadoop file system, Azure Data Lake, etc. These storages represent excellent choice for storing log data because their price is lower than Azure SQL or Cosmos DB, and generally it is faster to write log entries to the plain files because there is no additional overhead for data processing like in relational or even NoSQL databases. However, they represent cold storage with very limited query and analytic capabilities.
SQL Server enables you to load log files formatted as JSON from the cold storage, query and analyze log data using standard T-SQL language. If you are storing logs on file shares or Azure Blob storage, you can import files using BULK IMPORT command into the target table.
BULK INSERT Telemetry
FROM 'data/log-2018-01-27.json'
WITH ( DATA_SOURCE = 'MyAzureBlobStorageAccount');
In this example log entries are imported as one json log entry per row. Log entries stored on Hadoop can be loaded using Polybase external tables.
Once you load telemetry data in SQL tables, you can analyze it using standard T-SQL language. An example of T-SQL query that finds top 10 ip addresses that have accessed the system in some date period is shown in the following example:
SELECT TOP 10 JSON_VALUE(data, '$.ip'), COUNT(*)
FROM Telemetry
WHERE CAST(JSON_VALUE(data, '$.date') AS date) BETWEEN @start AND @end
GROUP BY JSON_VALUE(data, '$.ip')
ORDER BY COUNT(*) DESC
SQL Server and Azure SQL Database represent appropriate choice for ingesting telemetry data from cold storage in order to provide fast and rich analytics using T-SQL and wide ecosystem of tools that work with SQL Server and Azure SQL Database.
Information from devices and sensors in IoT applications might be sent either in structured or semi-structured format. If IoT devices don’t send fixed format, JSON is the preferred format for sending information from IoT devices.
Depending on the application needs, we have two possible paths for storing and processing IoT data:
[caption id="attachment_6055" align="alignnone" width="879"] Hot and cold path for storing IoT data in SQL Database[/caption]
Hot and cold path for storing IoT data in SQL Database[/caption]
Due to the large amount of IoT data that can arrive in SQL database, the recommended structure for storing semi-structured IoT data is a table with CLUSTERED COLUMNSTORE index, because it provides high compression and faster analytic. You can find more information about this scenario here .
Regardless of the path that is taken, IoT data that lands into SQL tables can be analyzed using standard T-SQL language and classing reporting tools such as PowerBI.
JSON support in SQL Server 2016+ and Azure SQL Database enables you to combine relational and NoSQL concepts and easily transform relational to semi-structured data and vice-versa. JSON is not a replacement for the exiting relational models, and there are some specific use cases when you should use JSON in SQL Database. In this post will be described the most common use cases when JSON in SQL Server could be used.
Simplification of complex data models
Classic relational databases force you to create highly normalized data models where high-level concepts such as Customer, Order, or Invoice are physically decoupled from their related entities such as Customer emails, Customer phones, Product parts, Order Line Items, Invoice tags, etc. Normalized models require high granularity of entities because they are designed to support a large number of independent transactions that are updating both conceptual entities and their parts at the same time. Breaking conceptual entities into the separate tables enables each transaction to update its own table without affecting others. The drawback of this approach is the fact that you need to get information from different tables to reconstruct one complex entity and its attributes, and also the fact that there is a risk of locks and even deadlocks if a transaction must atomically update several tables.
De-normalized models, on the other hand, merge the dependent entities into the main conceptual entities as cells with serialized collections and other complex objects. This way you need single lookup to retrieve or update the entity and all related data. However, this model is not suitable if you have frequent updates of related data.
The ideal model depends on the nature of your data and workload, so need to consider how the data will be used when you are choosing between normalization and de-normalization.
SQL Server and Azure SQL Database are general-purpose multi-model databases that enable you to combine the classic relational concepts with NoSQL concepts such as JSON, XML, and Graphs. Unlike classic relational and NoSQL database, SQL Database do not force you to choose between these two concepts – it enables you to combine the best characteristics of relational and non-relational models on the different entities in the same database in order to create an optimal data model.
[caption id="attachment_6155" align="alignnone" width="879"]
Difference between normalized and de-normalized models[/caption]
This way, you can have a set of standard relational tables with foreign keys and referential integrity, and complex data such as lists, arrays, collections, and dictionaries formatted as JSON or XML, spatial data or even graph relationships between the tables. SQL Server and Azure SQL Database enable you to fine tune design of your data model and use the most appropriate data structures depending on your use case.
If you have data models where related data are not frequently updated, you can store related entities in table cells as sub-collection formatted as JSON and combine simplicity of NoSQL design with the power of querying with SQL.
See example of de-normalization in action in this post .
REST API for single-page applications
Single-page applications represent the modern architecture for building web applications. They are based on the rich JavaScript application frameworks and libraries, and have a lot of client-side JavaScript code that is executing in the web browsers. Single-page applications communicate with backend systems via HTTP/AJAX requests that retrieve or send JSON messages to some REST APIs, which gets or stores data in the database. One of the main difficulties in web development is transformation of relation data into JSON messages and vice versa. In classic REST API you need to get the data from the database and transform it to JSON message that will be sent to your single-page application.
FOR JSON clause and OPENJSON function enable you to easily transform relational data stored in tables to JSON and to parse JSON text coming from the single-page applications into SQL database. This might be a perfect tool for building REST API for single page apps that communicate with backed system using JSON messages.
With JSON operators and functions, you can easily get the data from SQL tables or create complex reports using T-SQL, format results as JSON text and let REST API to return this text to some client-side app.
OPENJSON function enable you to get the JSON models sent by single-page applications, parse it and store it into a table.
See more details about building REST API for single page applications in this post , and an example that shows how to create REST API back-end to Angular application here .
Retail/E-commerce
Product catalog pattern is a common pattern in retail and E-commerce applications where you need to design a data structure that stores various types of products. The products in retail and e-commerce apps might have various properties/attributes. Depending on the type, some products might have dimensions and weight, others color, taste, price, number of doors, CPU, memory, etc. Attributes for this data may vary and can change over time to fit application requirements.
Designing a table that should store diverse types of products might be a challenge in classic relational databases because a large set of variable attributes cannot fit into the classic relational model. Data designers use different database design patterns such as wide sparse table, high normalization, or entity-attribute-value pattern to design variable attributes in a product catalog.
NoSQL databases are also a viable option for storing product catalog data because every product can be serialized as JSON document that contains only the properties that are applicable to the particular product type. However, in this case you need to have small and self-contained application where there are minimal interaction between products and other entities such as orders, customers, suppliers, etc. If these related entities are stored in the relational database, NoSQL is not an option because you have a central part of the domain model (product) disconnected from other entities.
With built-in JSON support, SQL database enables you to store variable attributes in a single cell formatted as JSON documents, like in NoSQL databases. See example of product catalog implementation in this post . The advantage of this approach is that product collections stored in SQL database are still connected to other tables in the database. In addition, you can apply the same indexing strategies on product catalog data formatted as JSON as you do on classic relational columns:
- NONCUSTERED indexes can be used to index values on some patch in JSON documents.
- Full-text search indexes can be used to index JSON data formatted as text.
Storing product catalogs in SQL database is preferred model if your product collection is tightly coupled with other entities in the database (for example orders, customers, invoices), because it enables you to query and join your product collection wit any other database entity.
Log and telemetry data analysis
Applications and devices generate large volumes of telemetry data, with information what happened in the app, error details, etc. Data can be formatted as plain text, delimited files (e.g. comma or tab separated values), JSON, etc. If you want to analyze plain text logs you might need to deal with complex parsing and regular expressions. CSV or TSV is easy for parsing; however, they require a fixed set of columns. JSON is in many cases chosen as a format for logs with trade-off between availability of parsing tools and flexibility of structure.
Telemetry data ends-up into log files that are stored on file systems, Azure Blob Storage, Hadoop file system, Azure Data Lake, etc. These storages represent excellent choice for storing log data because their price is lower than Azure SQL or Cosmos DB, and generally it is faster to write log entries to the plain files because there is no additional overhead for data processing like in relational or even NoSQL databases. However, they represent cold storage with very limited query and analytic capabilities.
SQL Server enables you to load log files formatted as JSON from the cold storage, query and analyze log data using standard T-SQL language. If you are storing logs on file shares or Azure Blob storage, you can import files using BULK IMPORT command into the target table.
BULK INSERT Telemetry
FROM 'data/log-2018-01-27.json'
WITH ( DATA_SOURCE = 'MyAzureBlobStorageAccount');
In this example log entries are imported as one json log entry per row. Log entries stored on Hadoop can be loaded using Polybase external tables.
Once you load telemetry data in SQL tables, you can analyze it using standard T-SQL language. An example of T-SQL query that finds top 10 ip addresses that have accessed the system in some date period is shown in the following example:
SELECT TOP 10 JSON_VALUE(data, '$.ip'), COUNT(*)
FROM Telemetry
WHERE CAST(JSON_VALUE(data, '$.date') AS date) BETWEEN @start AND @end
GROUP BY JSON_VALUE(data, '$.ip')
ORDER BY COUNT(*) DESC
SQL Server and Azure SQL Database represent appropriate choice for ingesting telemetry data from cold storage in order to provide fast and rich analytics using T-SQL and wide ecosystem of tools that work with SQL Server and Azure SQL Database.
Storing semi-structured IoT data
Information from devices and sensors in IoT applications might be sent either in structured or semi-structured format. If IoT devices don’t send fixed format, JSON is the preferred format for sending information from IoT devices.
Depending on the application needs, we have two possible paths for storing and processing IoT data:
- Cold path – IoT data can end-up into some cold/cheap cold storage such as file system or Azure Blob storage. IoT data can be loaded from the cold storage on-demand and analyzed using standard T-SQL language and tools such as PowerBI.
-
Hot path - If it is needed real-time analysis of IoT data, messages sent from the devices can be stored in directly into SQL Database. In this scenario, you have the following options:
- Parse incoming IoT data using OPENJSON function and store events in classic tables
- Store JSON data as-is and query it in the original format using JSON functions.
[caption id="attachment_6055" align="alignnone" width="879"]
Hot and cold path for storing IoT data in SQL Database[/caption]
Due to the large amount of IoT data that can arrive in SQL database, the recommended structure for storing semi-structured IoT data is a table with CLUSTERED COLUMNSTORE index, because it provides high compression and faster analytic. You can find more information about this scenario here .
Regardless of the path that is taken, IoT data that lands into SQL tables can be analyzed using standard T-SQL language and classing reporting tools such as PowerBI.
Updated Mar 24, 2019
Version 2.0JovanPop Microsoft
Microsoft
MicrosoftJoined March 07, 2019
SQL Server Blog
Follow this blog board to get notified when there's new activity