A common scenario in data warehousing applications is knowing what source system records to update, what data needs to be loaded and which data rows can be skipped as nothing has changed since they were last loaded. Another possible scenario is the need to facilitate searching data that is encrypted using cell level encryption or storing application passwords inside the database.
Data Hashing can be used to solve this problem in SQL Server.
A hash is a number that is generated by reading the contents of a document or message. Different messages should generate different hash values, but the same message causes the algorithm to generate the same hash value.
|
The HashBytes function in SQL Server |
|
SQL Server has a built-in function called HashBytes to support data hashing.
HashBytes ( '<algorithm>', { @input | 'input' } )
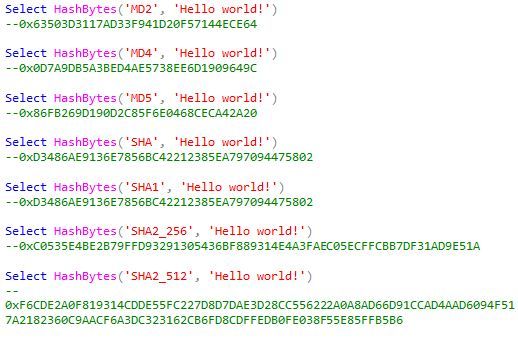
Here is a sample along with the return values commented in the next line :
|
|
Properties of good hash functions |
|
A good hashing algorithm has these properties:
|
|
Should you encrypt or hash? |
|
During application development, it might be useful to understand when to encrypt your data vs. when to hash it. The difference is that encrypted data can be decrypted, while hashed data cannot be decrypted. Another key difference is that encryption normally results in different results for the same text but hashing always produces the same result for the same text. The deciding factor when choosing to encrypt or hash your data comes after you determine if you'll need to decrypt the data for offline processing. A typical example of data that needs to be decrypted would be within a payment processing system is a credit card number. Thus the credit card number should be encrypted in the payment processing system. However, in the case of security code for the credit card, hashing it is sufficient if only equality checks are done and the system does not need to know it’s real value.
Encryption is a two way process but hashing is unidirectional |

|
How to use hashbytes for indexing encrypted data. |
|
Encryption introduces randomization and in there is no way to predict the outcome of an encryption built-in. Does that mean creating an index on top of encrypted data is not possible? However, data hashing can come to your rescue. Refer to this blog post to learn how. |
|
Which hash function should I choose? |
|
Although, most hashing functions are fast, the performance of a hashing function depends on the data to be hashed and the algorithm used. There is no magic bullet. For security purposes, it is advised to use the strongest hash function (SHA2_512). However, you can choose other hashing algorithms depending on your workload and data to hash. |
|
Hash functions or CHECK_SUM()? |
|
SQL Server has the CHECK_SUM () (or BINARY_CHECKSUM ()) functions for generating the checksum value computed over a row of a table, or over a list of expressions. One problem with the CHECK_SUM() (or BINARY_CHECKSUM()) functions is that the probability of a collision may not be sufficiently low for all applications (i.e. it is possible to come across examples of two different inputs hashing to the same output value). Of course, collisions are possible with any functions that have a larger domain than its range but because the CHECK_SUM function implements a simple XOR, the probability of this collision is high. Try it out using the following example -
|

---
Don Pinto, PM, SQL Server Engine
