Hello all,
A while back I blogged here about how a good strategy of log file growth could potentially impact ongoing operations with your SQL Server. It’s known that VLFs (number and size) impact on the performance of such actions as scanning all VLFs for transactions that are marked for replication or log backup operations. Following that blog post, I became curious as to how having a poor strategy could potentially impact some less than obvious operations within SQL Server and decided to put that to a test..
As someone who works with SQL Server, or any relational database system for that matter, you are probably aware that whatever actions happen in the storage structures of a database gets recorded (DDL and DML), depending of course on the logging level of that database, set by the recovery model. So lets just do a quick overview (and that may be an understatement) of what is a log file and how SQL Server handles log usage. So each of the changes the database storage structures has its own log record describing where and what has changed, and these changes are in effect called transactions. The ordered recording of these transactions is what allows changes to be replayed or reversed in a variety of scenarios, from recovery to transaction replication, or even standby server solutions like database mirroring or log shipping, for example.
As for the log structure itself, it is well documented in Books Online and various other resources I mentioned
here
, so I won’t get into much detail.
For the scope of this blog post, the concepts that need to be conveyed are that SQL Server allocates log space in logical sections called Virtual Log Files (VLFs) within each physical log file, and depending on the logging level of that database, there are several actions that trigger something called log truncation, which is the action of freeing any virtual logs before the VLF that contains the minimum recovery log sequence number. In reality, “freeing” a VLF is just changing its status to unused. In turn, the minimum recovery log sequence number (MinLSN) is the log sequence number of the oldest log record that is required for a successful database-wide rollback. As for the log truncation action itself, it’s achieved after all the records within one or more virtual log files become inactive, and allows for a stable log file size by using VLFs in a round-robin fashion (wrap-around), given that nothing is deferring this default behavior, like data backup or restore operations, long running active transactions, amongst others issues. Please note that log truncation does not reduce the size of a physical log file, it reduces the size of the logical log file. If the log is not being truncated after routine log backups and keeps growing, something might be delaying log truncation, but that is a matter of future blogging on its own right, so let’s move on.
I set out to answer a question in the back of my mind: if DML gets logged, shouldn’t it also be affected by issues with VLFs? So I made a few benchmarks to see how far a poor log file management strategy could interfere in DML performance with two different scenarios - high and low number of VLFs.
That being said, the test setup is comprised of a VM with 1,5GB of RAM and 2 contiguous 20GB VHDs on my 64-bit laptop (Core2 Duo at 2.5Ghz, running Windows Server 2008 and SQL Server 2008 SP1). Then two databases were needed in this test case, both with a 5120MB data file and a 2048MB log file, growth limited to 2192MB on the log and unlimited on the data file. Both have the same file growth size on the data file, which will not grow at all for the duration of the tests. Here is the DDL:
CREATE DATABASE [HighVLF] ON PRIMARY
( NAME = N'HighVLF', FILENAME = N'E:\Data\HighVLF.mdf' ,
SIZE = 5120000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 262144KB )
LOG ON
( NAME = N'HighVLF_log', FILENAME = N'F:\Log\HighVLF_log.ldf' ,
SIZE = 1024KB , MAXSIZE = 2192000KB , FILEGROWTH = 1024KB )
GO
CREATE DATABASE [LowVLF] ON PRIMARY
( NAME = N'LowVLF', FILENAME = N'E:\Data\LowVLF.mdf' ,
SIZE = 5120000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 262144KB )
LOG ON
( NAME = N'LowVLF_log', FILENAME = N'F:\Log\LowVLF_log.ldf' ,
SIZE = 1024KB , MAXSIZE = 2192000KB , FILEGROWTH = 1024000KB )
GO
- LowVLF DB (log grown by 1024MB increments) spawning 20 VLFs.
- HighVLF DB (log grown by 1MB increments) spawning 8000 VLFs.
The results showed an impressive 70% overtime (on average) when growing by shorter amounts and spawning more VLFs.

So here we see a clear example of how growing more times with less amounts can indeed be more costly, with added effects by generating much more logging for the growth iterations themselves. So, pre-growing files (in this case a log) does sound like a good practice. Imagine how much more I/O effective a system would be if it wasn’t being hammered in the middle of production hours by auto-growing files, like most I/O bound systems are.
BACKUP DATABASE LowVLF to disk = 'c:\lowvlf.bak' WITH stats = 1
GO
BACKUP LOG LowVLF TO DISK = 'c:\low1.trn'
GO
BACKUP DATABASE HighVLF to disk = 'c:\highvlf.bak' WITH stats = 1
GO
BACKUP LOG HighVLF TO DISK = 'c:\high1.trn'
GO
Then the exact same table was created on both databases and populated with 1 record only.
CREATE TABLE vlf_test
(
a int identity(1,1) not null,
b char(8000) not null,
c int not null
)
GO
INSERT vlf_test VALUES (REPLICATE('a',8000),0)
GO
So after that it’s just a matter of starting 40000 update loops on the same row (actually 2 updates on column b within each loop) and monitor it to see VLF usage increasing.
SET NOCOUNT ON
BEGIN TRAN
DECLARE @x int, @a char(8000), @b char(8000)
SET @a = REPLICATE('a',8000)
SET @b = REPLICATE('b',8000)
SET @x = 1
WHILE @x<>40000
BEGIN
UPDATE vlf_test SET b = @a, c = @x WHERE a = 1
UPDATE vlf_test SET b = @b WHERE a = 1
SET @x = @x + 1
END
COMMIT TRAN

Well, because my databases are not so large, I purposely left auto-grow come into effect in a 2nd benchmark (which is a real scenario in most servers), to further impact on this test and demonstrate how the growth factor is also a part of this equation. So here are the results:

A big difference, as expected given the amount of time to pre-grow the logs and do the update loop itself. What about backups? As I’ve said earlier, log backup times are very much affected by the sheer number of VLFs, and the numbers show it clearly. For roughly the same amount of pages, a log backup of the HighVLF database took almost twice the time of the LowVLF database.
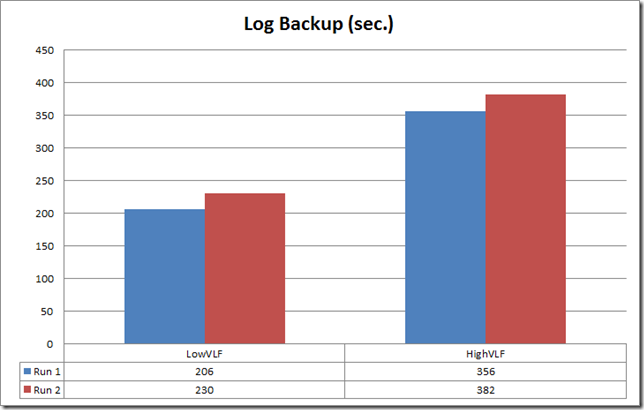
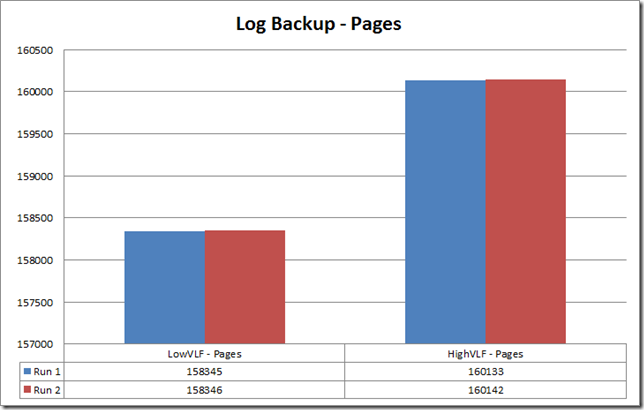
It’s arguable as to how much an effect would these findings have on high-end systems, but just take into account that on these, the transactional load is also much heavier and most probably more resource intensive, and I/O an even more precious resource. In conclusion, it’s fair to claim that having fewer VLFs will almost always have measurable effects in performance for some DML, and even more so when fewer growth iterations are occurring.
References:
Technet Magazine - Understanding Logging and Recovery in SQL Server by Paul Randal
Transaction Log Physical Architecture
Until next time!
Disclaimer: I hope that the information on these pages is valuable to you. Your use of the information contained in these pages, however, is at your sole risk. All information on these pages is provided "as -is", without any warranty, whether express or implied, of its accuracy, completeness, fitness for a particular purpose, title or non-infringement, and none of the third-party products or information mentioned in the work are authored, recommended, supported or guaranteed by Ezequiel. Further, Ezequiel shall not be liable for any damages you may sustain by using this information, whether direct, indirect, special, incidental or consequential, even if it has been advised of the possibility of such damages.