With Cluster Shared Volumes (CSV) one of the nodes in the cluster is responsible for synchronization of access to files on a shared volume. This is the node which currently owns the cluster ‘Physical Disk’ resource associated with that LUN, which is referred to as the Coordinator node. Each LUN can have its own coordinator and all nodes are equal and could be a coordinator, so it could be any node. When a VM is deployed and running on a CSV volume almost all of Hyper-V’s access to VHD files associated with a VM go directly to the disk and the coordinator node is not involved. This enables VMs to have fast direct access and give great performance for the VM and the applications running within the VM. So it really doesn’t matter which node is the coordinator or where VM’s are running.
With Windows Server 2008 R2 one exception to that happens when you are copying VHD files to CSV volumes as you create and deploy your VMs. As you copy/create the VHD files to a CSV volume, those writes to the disk are extending write operations, and, as a result, they are redirected over the network to the coordinator node. This can result in it taking longer to copy the file. The moral of the story is that when you are going to do a file copy to a CSV volume, to get the greatest performance it is best to do the copy on the coordinator node if you are doing a local copy. If you are doing a remote copy over the network, it’s best to have the coordinator node be the target of the copy. You can view the current owner or even move ownership of Physical Disk resources from one node to another with the Failover Cluster manager snap-in (CluAdmin.msc) or PowerShell. So you can make whatever node you are on the coordinator.
Note: With Windows Server 2012 an extending write operation will be done with direct I/O, and these considerations do not apply.

Or, use PowerShell with the Get-ClusterSharedVolume CMDlet:

To give an example, on my 2-node cluster, I tried making a copy of a VHD file (6.4 GB) from a local path to my CSV volume where I want the VHD file to live. What you will see is that depending on which node I initiated the file copy from, the time it took to copy the file varied.
Here is what I did: I made a copy of the same file onto a local folder on each cluster node, then I tried making a copy of that file to the same CSV volume (with different destination file names) on both cluster nodes. But, I noticed that on one node, it took me just over 2.5 minutes (first screen shot), while on another node it took me just under 3.5 minutes (second screen shot).
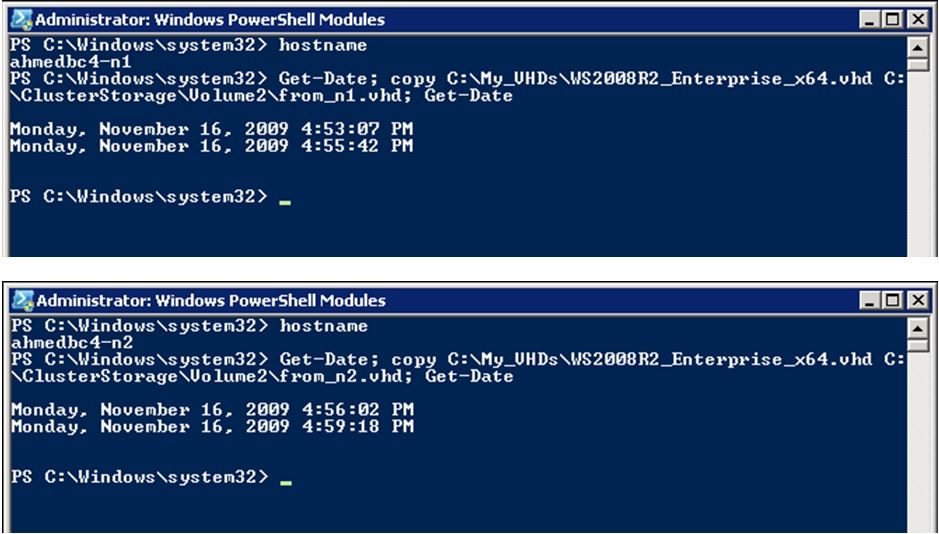
Although both copy operations seem to be “local” (I’m copying from the same file from C:\My_VHDs to C:\ClusterStorage\Volume2 on both nodes), the copy was taking more time to complete on Node2 (3.5 minutes) compared to performing the same operation on Node1 (2.5 minutes) because Node1 was the coordinator node for the destination CSV volume. On that node, the writes are all local writes because it is the coordinator itself. From the other node, Node2, the writes are actually redirected over the network to Node1 (because they are extending writes to the file).
So, what does that really mean?
The bottom line here is that if you’re trying to make copies of files to CSV and you want to get this copy to complete in the fastest possible time, make sure you do the copy on the coordinator node.
If you want to learn more about CSV, there is a lot of material out there that you can refer to:
· http://technet.microsoft.com/en-us/library/dd759255.aspx
· http://technet.microsoft.com/en-us/library/dd630633(WS.10).aspx
· http://blogs.msdn.com/clustering/archive/2009/03/02/9453288.aspx
· http://blogs.msdn.com/clustering/archive/2009/02/19/9433146.aspx
Regards,
Ahmed Bisht
Senior Program Manager
Clustering & High-Availability
Microsoft