We live in an imperfect world, where things will go wrong. When they do, you need a private cloud which is designed to be highly available and resilient to failures in the environment. In today’s cloud scale environments transient storage failures have become more common than hard failures. Transient storage failure means that a Virtual Machine (VM) cannot access the VHDX file and that read or write requests to the disk are failing. In Windows Server 2016 there is new Hyper-V capabilities which will enable a VM to detect when storage access fails and to be seamlessly resilient. In short, by moving your private cloud to Windows Server 2016 your VMs will achieve better SLA’s!
What happens when VM experiences transient storage failure
What happened in Windows Server 2012 R2
The behavior in previous releases is that when a Virtual Machine (VM) experienced a failure in reading or writing to its virtual hard disk (VHD/X), than either the VM or applications running inside the VM would crash. This is obviously very disruptive to the workload (to say the least)!.
What happens in Windows Server 2016
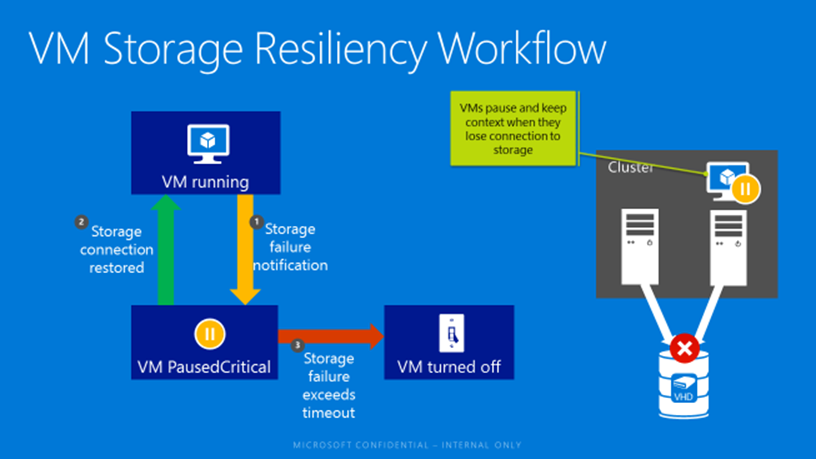
In Windows Server 2016 new capabilities have been introduced which detects the storage failures and takes action to mitigate the impact. When a VM experiences a failure in readying or writing to its VHD/VHDX the VM will be placed into a critical pause state. The VM is frozen in time, resulting in everything inside the VM freezing and no additional I/O’s are issued. The VM will remain in this state until storage becomes responsive again. The VM then moves back to running state when it can start reading and writing to its VHD/X. Since the session state of the VM is retained, this means the VM resumes exactly where it left off. For short transient failures, this will commonly be completely transparent to clients.
Remember that when a VM is in a critical pause state, the VM is frozen and not accessible to clients. So there is a window where clients will not be able to access the VM. But the fact that the VM session state is retained, makes the storage outage much less impactful.
A VM will not stay in a critical pause state indefinitely, if storage access cannot be regained within the configurable timeout, the VM is then powered off and the next start will be a cold boot.
Configuration Options
This new functionality is an integrated part of Hyper-V and you do not need to do anything to take advantage of it. You can configure virtual machine storage resiliency options that defines behavior of the virtual machines during storage transient failures
-
Enable / Disable
– If you wish to revert to the behavior of previous releases, the storage resiliency enhancements can be disabled on a per VM basis. It is enabled by default.
PowerShell syntax:
Set-VM -AutomaticCriticalErrorAction <None | Pause>
-
Timeout
– The amount of time a VM remains in critical pause state before powering off can be configured on a per VM basis. The default value is 30 minutes.
PowerShell syntax:
Set-VM –AutomaticCriticalErrorActionTimeout <value in minutes>
Shared VHDX
Shared VHDX is usually used where multiple VMs are sharing a storage space and form a guest cluster to provide high availability for applications running inside the VM. For a guest cluster there is resiliency at the application layer inside of the VM, so the preferred behavior is to have failover occur to another VM. The new storage resiliency feature is aware and optimized to provide the best behavior for a Shared VHDX. When a VM experiences a failure in reading and writing to its Shared VHDX than connection of the Shared VHDX is removed from the VM. This results in clustering within the VM to detect the storage failure and take recovery action. Unlike a normal VM, a VM with a Shared VHDX does not go into critical pause state and the guest cluster moves its workload to another VM which is also part of the cluster and has access to shared VHDX. The VM which has lost connection to its Shared VHDX will poll it every 10 minutes to check if storage access has been restored. As soon as it gets access to it, the Shared VHDX is reattached to VM.

When can I use storage resiliency
VM storage resiliency is supported with:
- Gen1 and Gen2 VMs
- VHD, VHDX and Shared VHDX
-
Local block storage (SAN)
- FC, iSCSI, FCoE, SAS with Cluster Shared Volumes
-
File Based storage (NAS)
- File shares using SMB (Server Message Block protocol) with Continuous availability such as a Scale-out File Server (SoFS)
Storage resiliency is not supported with:
- VHD / VHDX on a local hard disk without Cluster Shared Volumes
- Standard file servers
- USB storage
- Hyper-V pass-through disks
In short, Windows Server 2016 will handle transient failures storage failures gracefully.
Thank you,
Tushita
 Microsoft
Microsoft