As a follow-up to my http://blogs.msdn.com/b/mattm/archive/2009/11/13/handling-slowly-changing-dimensions-in-ssis.aspx , I thought I’d go deeper into using the built-in http://msdn.microsoft.com/en-us/library/ms141715.aspx . While there are definitely more efficient ways to do SCD processing in SSIS, there are some optimizations you can apply to the components that the wizard outputs that might make it more acceptable for your environment.
First, let’s take a look at the Wizard’s strengths. Besides the advantage of not having to write any SQL by hand, there are two key scenarios the SCD Wizard is optimized for:
- Small number of change rows - Most ETL best practices say that you should perform change data capture (CDC) at the source (or as close to the source as possible). The Wizard was not designed to process your entire source table (like the Kimball Method SCD component) – for example, it doesn’t detect “deletes”.
- Large dimensions – If you are dealing with large dimensions, SCD approaches that read the entire reference table may not be the best approach. For example, if I have 5-10K change rows coming in, and a 2 Million row dimension, the majority of the data flow time will be spent doing a full scan of your source dimension table.
If your scenario doesn’t match the above, you might want to consider just using one of the alternate approaches directly. If it does, or if you don’t want to use any custom components (or hand craft the http://www.kimballgroup.com/html/08dt/KU107_UsingSQL_MERGESlowlyChangingDimension.pdf , for example), consider making the following optimizations:
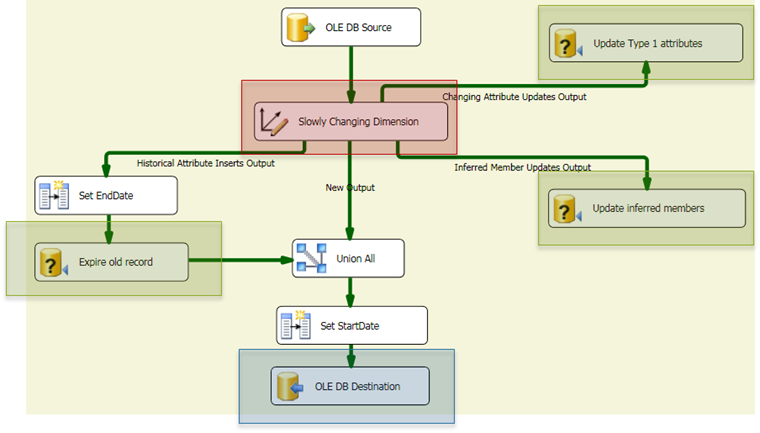
Slowly Changing Dimension transform (Red)
The first transform does not cache any lookup results from the reference dimension, so every incoming row results in a query against the database. By default, the wizard will open a new connection to the database on each query. For a performance gain (and less resource usage), you can set the RetainSameConnection property of the wizard’s connection manager to True to re-use the same connection on each query.
OLE DB Command transforms (Green)The wizard will output three separate OLE DB Command transforms (which perform row-by-row updates). You will get a big performance boost by placing the rows in a staging table, and performing the updates in a single batch once the data flow completes. Another option is to use the http://agilebi.com/cs/blogs/jwelch/archive/2008/10/21/a-merge-destination-component.aspx , which is available on http://ssisctc.codeplex.com/wikipage?title=Batch%20Destination&referringTitle=Home .
OLE DB Destination (Blue)The default destination that the Wizard outputs will have http://msdn.microsoft.com/en-us/library/ms188439.aspx disabled (to avoid locking issues). In many cases (mostly depending on the number of rows you’re processing), you can enable Fast Load for an immediate performance gain. To avoid potential deadlocking issues, another option is to use a staging table, and move the data over to the final destination table once the data flow is complete using a INSERT INTO … SELECT statement.
Using the above optimizations, I was able to bring down the processing time of a 200k row change set (against a 100k row dimension table) from 60 minutes to 14 minutes. Note however, that processing a similar change set using the SQL MERGE statement took under 3 minutes to complete.

I go into more detail about these optimizations (and the difference between SCD processing approaches) in my http://blogs.msdn.com/b/mattm/archive/2010/06/29/ssis-performance-design-patterns-video.aspx .