This post demonstrates how you can create a matching policy in a knowledge base and tune it to achieve best results. The screenshots were taken from a later DQS build so you will probably notice some changes to the user interface and functionality comparing to the CTP3 build.
What is a Matching Policy?
Y ou prepare a matching policy in a knowledge base to define how DQS identifies duplicate records. A matching policy consists of one or more matching rules that assess how well one record matches to another, based on parameters each domain carries in the matching rule. You specify in the rule whether records’ values have to be an exact match, similar, or prerequisite (these properties are described in the “Create Matching Policy” section).
The matching policy activity analyzes sample data by applying each matching rule to compare two records at a time throughout the range of records. Records whose matching scores are greater than a specified minimum are grouped in clusters in the matching results. When you complete preparing your matching policy, it is saved with the knowledge Base and is publicly available when you publish the Knowledge Base. You can then use the Knowledge Base in a Matching Project to apply the rules you created on your source data to identify duplicate records.
Initial Matching
A rmed with cleansed data obtained from a Data Quality Cleansing Project, DQS’s core matching technology is ready for action. DQS’s matching engine relies on a technology that is capable of identifying relationships between essentially identical records within both structured and unstructured data. These relationships are quantified into a set of weighted probability conditions, which can then be applied to accurately identify matched records within a dataset. It is important to note that this system works equally well on any type of data in any language. The relationships and conditions are determined based on the data itself and by a knowledge base created for that purpose. If data domain values are available in the knowledge base, including their synonyms and syntax errors, they are utilized by DQS matching engine to improve performance and the accuracy of the matching results.
Just as the electric starter used to start an automobile engine, a powerful initial matching system is invoked to jump-start the primary matching engine. Based on the knowledge accumulated in the knowledge base, DQS is able to start proposing potential matching candidates from within the customer’s actual dataset. This initial matching “starter” is capable of identifying a substantial percentage of likely matches from within the data. User interaction is required at this stage. A person familiar with the data approves or rejects the matching candidates proposed by the matching engine.
Knowledge Based Matching
L et’s roll back the wheels a bit. In the previous paragraph, I have mentioned that the matching engine is using a knowledge base for identifying potential matching candidates. So what is this knowledge? Well, the bread and butter element that is required for running a matching project is the Matching Policy. With no further ado, let’s jump in and start creating a matching policy.
Creating a Matching Policy
Step 1. Know your data
T he Matching Policy is one of three activities available for creating and expanding the knowledge in existing knowledge base. You can start by either creating a new Knowledge Base or opening an existing one. I will describe the first scenario.
Before you approach the Matching Policy activity, you should have some understanding of your data; it is important to make some assessments and do some planning before jumping into creating your matching policy, for example, what is the entity you wish to find duplicates for and what are the attributes that fundamentally describes it. There is a tendency to use every available attribute under the belief that the more information, the better…you probably want to consider matching on attributes that provide the most highly identifiable and discriminatory information, such as Name (first, last, company name). Gender (which rarely changes) and address.
Aha…one more thing, about performance…

You can start by utilizing the Prerequisite property for a domain in a matching rule to proactively minimize the exhaustive computation, and reduce the size of potential matches population; then, apply the Similar property on other domains that require a Fuzzy comparison (usually on names). For instance, you could apply the Prerequisite property to ‘Country’, State’, ‘City’ and ‘Postal Code’ and use the Similar property on a Name domain (customer name, company name etc.). The definition of these properties is depicted in the next paragraph.
Failing to optimize a matching policy will probably encourage you to take some time off on a remote island… https://msdnshared.blob.core.windows.net/media/MSDNBlogsFS/prod.evol.blogs.msdn.com/CommunityServer.Blogs.Components.WeblogFiles/00/00/01/45/78/3362.Remote%20island2E002E00.jpg
Step 2. Creating Matching Rule(s)
By now, you should know your data structure and business requirements for matching your data. You can start creating a matching policy by creating a new Knowledge Base.
1. Select the Matching Policy activity then click Next.

2. Select your data source, which can be either a SQL table/view or Excel.
3. Select the columns you desire to match, create a domain for each column then click Next.

4. Click the ‘Create a matching rule’ button on the left pane to create a new matching rule.

5. Add the domains you wish to match on the right pane in the rule editor.
6. Repeat the following steps for all other domains that will be part of the matching rule:
-
For
Similarity
, select Similar if two values in
the same field of two different records can be considered a match even if not
identical. Select Exact if two values in the same field of two different
records must be identical to be considered to be a match; if not identical, the
matching score for that domain will be set to “0”, and processing of the rule
will proceed to the next condition (domain). -
For
Weight
, enter a value that determines the
contribution of a domain’s matching score to the overall matching score for two
records. -
Select
Prerequisite
to specify that the values for
the field in the two records must return a 100% match, else the records are not
considered a match and the other domains in the rule are disregarded. A Prerequisite
domain does not contribute to the overall matching score between two records;
you will notice that the Weight property for that domain is removed so that you
cannot define a weight for the domain in the rule. Using this property
dramatically reduces computation and thus yields faster results. It is highly
recommended utilizing this property as described in the previous paragraph
(step 1). -
Ensure that the sum of the weights for all domains in the
rule equals 100 -
The
minimum matching score
is the threshold at or
above which two records are considered to be a match (and the status for the
records is set to “Matched”. Increase
the value of the Min. matching score if you want to make the matching
requirements more stringent.
7. Repeat steps A through E for any additional rule you wish to add to your matching policy.
You are now ready to train you matching policy. The next paragraph describes the execution of a matching rule and the information on the Profiler panel that can be of use for tuning the policy.
Step 3. Training Your Matching Policy
A
n individual rule is executed from the rule editor pane (matching policy step); click Start to run the matching process for the selected rule. When the process is complete, the table displays the Record ID (created by the DQS matching engine), Cluster number, and data columns (including those not in the matching rule) for
each record in a cluster. The pivot record in the cluster is the leading record (randomly selected during the matching computation); each additional row in a cluster is considered a duplicate. The matching score reflects the weighted similarity score between the duplicate and the pivot record.
Now let’s take a closer look at the following screenshot. The first matching rule says:
- Match ‘Address Line 1’ using the Similar property (not showing on the screenshot)
- Match domain ‘City’ as Prerequisite (not showing on the screenshot)
- Match ‘State’ as Prerequisite
- Match ‘Postal Code’ as Prerequisite
- Match ‘Full Name’ domain using the Similar property

In order to tune the matching policy I will use my ‘detective’ skills in conjunction with the information provided by the Profile nd Matching Results tabs (lower part of the screen).
Profiler Tab:
T he level of Completeness in the columns I selected to match is high therefore there is no need to drop any of them from the matching rule. Pay attention to the level of completeness in your data and avoid adding columns with low completeness to a matching rule.
The
Unique
column provides some interesting information about the uniqueness of the values in each column; you can use this information to optimize your matching rules to achieve better results and
performance. For instance:
- Columns having a Low uniqueness count will provide discriminatory information although they may not provide highly identifiable information (e.g., City, State etc.). These columns can be set as Prerequisite , especially if they have been well cleansed.
-
Columns having a
High uniqueness count
provide highly identifiable information and are highly discriminatory (discriminatory has to do with how well the field can discriminate between two records) and thus can be defined with a higher Weight. As for the Similar property, it depends on the quality of the data in these columns and whether they have been well cleansed; if the data was not cleansed then you probably want to set this property to
Similar
instead of
Exact
; it is always recommended to cleanse your data before matching.
https://msdnshared.blob.core.windows.net/media/MSDNBlogsFS/prod.evol.blogs.msdn.com/CommunityServer.Blogs.Components.WeblogFiles/00/00/01/45/78/6886.Profiler%20Pane.jpg

Matching Results Tab:
T he Matching Results tab displays statistics for the current and previous run of a matching rule. If you have run the same rule more than once with different parameters, the matching results table will display statistics for both runs, enabling you to compare them. You can also restore the previous rule if you would like. The purpose of this functionality is to reduce the number of tuning iteration you apply on your matching rule.
In the first screenshot below you can see that the Current run of the matching rule yielded more duplicates than the previous run; but looking closely, many of them are False Positives (false matches) - see the second image; therefore I would restore the previous rule…and increase the minimum matching score (above 60%) to exclude false positives (false matches).


M
atching Policy Examples
I must emphasize that a Matching Policy you have prepared for one type of data may not necessarily fit other types of data. Each data source may contain different attributes and different level of quality; when you train your matching policy, you need to take into consideration parameters as completeness, uniqueness, level of cleansing etc. these vary from on data source to another. Nonetheless, if the data sources share the same attributes, you could reuse the matching policy on your different sources (paying attention to the parameters I have described above).
Let’s examine two entities that are very common, Companies and Customers; two different data entities that share common attributes; they both contain address attributes. For both matching policies you could set up the address domains as Prerequisite and define the ‘Company Name’ or ‘Customer Name’ to be matched as Similar ; often the level of uniqueness for these attributes is high (names), therefore I would define a higher weight on these domains in the matching rule.
The following figures depict the Matching Policies for each data source (company and customer).
Matching Policy for ‘Customer’

Matching Policy for ‘Company’
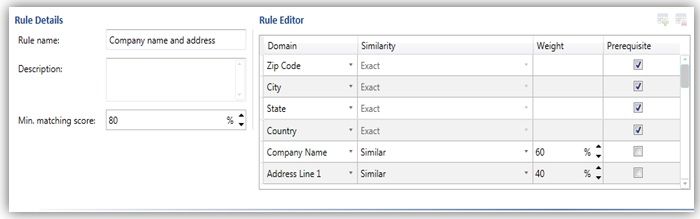
It is time to wrap-up, I hope that this information will get you started; make sure you understand your data before you start preparing your matching policy.
…..and keep in mind that it’s always better to start with the low hanging fruits…they simply taste better

Other Resources
Watch the videos about creating a matching policy and matching data on Technet, under the Videos section: http://technet.microsoft.com/en-us/sqlserver/denali_resource_center.aspx
- Gadi Peleg, DQS