NOTE: The content of this article has been published in the official Exchange 2007 documentation. We recommend that you check the documentation for the most up-to-date version. Please go here:
http://technet.microsoft.com/en-us/library/bb124518(EXCHG.80).aspx
Edit: this post has been updated on 7/3/07, updates from previous versions are listed here.
Introduction
This is the final blog in my series about Exchange 2007 storage. In this blog I will tie together all of the content from previous blogs to outline our recommendations for configuring, validating, and monitoring your Exchange storage solution.
There are four key objectives to this blog.
- Understand what information you need to correctly design a storage solution for Exchange 2007.
- Apply hardware and technology to these storage designs.
- Validate the storage design.
- Monitor the storage design.
Capacity and performance are often at odds with each other when it comes to physical disks, and both must be considered before making a purchasing decision. The first concern is whether there will be enough space to store all of the data. The second concern is that the transactional I/O must be measured or predicted to ensure that the solution also meets the performance requirements for acceptable disk latency and a responsive end user experience. The third concern, is to ensure that the non transactional I/O has both enough time to complete, and enough disk performance and throughput to meet the required service level agreement (SLA). The Holy Grail is to take these three parts and find a balance in the design of the actual hardware to meet all four objectives.
Capacity
Having enough capacity is absolutely critical. When a database LUN runs out of space, the databases on that LUN will dismount. When a transaction log LUN runs out of space, it will cause all of the databases in that storage group to dismount. Provisioning additional space is often hard to do quickly, and performing an offline compaction could take a long time. In most cases running out of disk space will result in an interruption of availability for one or more databases for a period of time that typically exceeds most recovery time objectives (RTO).
Mailbox Size\Mailbox Count
The first metric to understand is mailbox size. The amount of data an end user is allowed to store in their mailbox will help in determining how many users can be housed on the server. While final mailbox sizes and quotas can and do change, having a goal in mind is the first step in determining your needed capacity. For example, if you have 4000 users on a server with a 250MB mailbox quota, then you need at least 1TB of disk space. Moreover, there are additional components which must be factored into the equation. If a hard limit is not set on the mailbox quota, it is difficult to estimate the how much capacity you will need.
Database Whitespace
The database size on the physical disk isn't just the number of users multiplied by the user quota. When the majority of users are not near their mailbox quota, the databases will consume less space and whitespace isn't a capacity concern. The database itself will always have free pages, or whitespace, spread throughout. During online maintenance, items marked for removal from the database are removed, freeing up these pages. The percentage of whitespace is constantly changing with the highest percentage immediately after online maintenance, and the lowest percentage right before online maintenance.
The whitespace in the database can be approximated by the amount of mail sent and received by its users. For example, if you have 100 - 2GB mailboxes (200GB) in a database that send and receive an average of 10MB of mail per day, the whitespace would be approximately 1GB (100*10MB).
Whitespace can grow beyond any approximation if online maintenance is not able to complete a full pass. It is important that enough time is allocated for online maintenance to run each night, so that a full pass can complete within one week or less.
Database Dumpster
Each database has a dumpster that stores hard deleted items. By default, items are stored for 7 days in Exchange 2003, and 14 days in Exchange 2007. These include items that have been purged from the deleted items folder. Exchange 2007 will increase the overhead consumed by the database dumpster, because deleted items will now be stored for twice as long.
After the retention period has passed, these items will be removed from the database during an online maintenance cycle. Eventually, a steady state will be reached where your dumpster size will be equivalent to 2 weeks worth of incoming mail as a percentage of your database size. The exact percentage will depend on the amount of mail deleted and on individual mailbox sizes. The dumpster will add a percentage of overhead to the database dependent upon the mailbox size and the message delivery rate for that mailbox. For example, with a constant message delivery rate of 52MB a week, a 250MB mailbox would store approximately 104MB in the dumpster adding a 41% overhead. A 1GB mailbox storing the same 104MB in the dumpster would add a 10% overhead.
Database Size
Over time, user mailboxes will reach the mailbox quota, so an amount of mail equivalent to the incoming mail will need to be deleted in order to remain under the mailbox quota. This means that the dumpster will increase to a maximum size equivalent to two weeks' worth of incoming mail. If the majority of users have not reached the mailbox quota, only some of the incoming mail will be deleted, so the growth will be split between the dumpster and the increase in mailbox size. For example, if you take a 250MB very-heavy message profile mailbox that receives 52MB of mail per week (average message size 50KB), you'd have 104MB in the dumpster (41%), and 10MB in whitespace for a total mailbox size of 364MB. The other extreme could be a 2GB very-heavy message profile mailbox that received 52MB of mail per week, and then you'd have 104MB in the dumpster (5%), and 10MB in whitespace for a total mailbox size of 2.11GB. Fifty 2GB mailboxes in a storage group would be 105.6GB.
Here is a formula to show database size with the 2GB mailbox example:
MailboxSize=MailboxQuota+Whitespace+(WeeklyIncomingMail*2)
MailboxSize=2048MB+(10MB)+(52MB*2)
2162MB =2048MB+10MB+104MB or 6% larger than the quota
Recommended Maximum Database Size
Smaller databases are always better, but your sizing needs to be balanced with other factors, especially capacity and complexity. Larger databases will take longer to backup and restore, while immediately deploying with the maximum of 50 databases, will add complexity with more databases and LUNs to manage. With Exchange 2007 the maximum number of databases per server is increased from 20 to 50. On servers that don't use continuous replication, we recommend that you limit the database size to 100GB. On servers that use continuous replication, we recommend that you limit the database size to 200GB. For more information, see Planning Disk Storage.
SG/DB Count
To determine the maximum number of users per database, take the projected mailbox size and divide it by the maximum recommended database size. This will also help you determine how many databases you will need to handle the projected user count, assuming fully populated databases. Keep in mind, though, that due to non-transactional I/O or because of hardware limitations, you may eventually have to modify the number of users placed on a single server. Some administrators will prefer to use more databases to further shrink the database size. This can assist with backup and restore windows at the cost of more complexity in managing more databases per server. For more information on memory recommendations, see Planning processor and Memory Configurations.
Content Indexing
Content indexing creates an index, or catalog that allows end users to easily and quickly search through their mail items than manually trolling through the mailbox. Exchange 2003 created a content index that was ~35-45% the capacity of your database. In that version of Exchange, content indexing is a disk-intensive, scheduled crawl through the database. Exchange 2007 creates an index that is only about 5% of the total database size, which placed on the same LUN as the database it is indexing, on stand alone and CCR servers. An additional 5% capacity needs to be factored into the database LUN size for content indexing.
Database Growth Factor
For most deployments we recommend that you add an overhead factor (aka "fluff factor") of 20% to the database size (after all other factors have been considered) when creating the database LUN. This value will account for the other data blobs that reside in the database that are not necessarily seen when calculating mailbox sizes and whitespace; for example, deleted mailboxes within the retention policy and the data structure (e.g. tables, views, internal indices, etc.) within the database adds to the overall size of the database. Now that you have the actual database size and understand how content indexing adds to the capacity needs, you need to add an overhead factor to it when creating the actual database LUN.
Maintenance Capacity
A database that needs to be repaired or compacted offline will need capacity equal to the size of the target database plus 10%. Whether you allocate enough space for a single database, a storage group, or a backup set, this space needs to be available to perform these operations. This space can also be used when restoring a corrupted database. You can rename the corrupted database to prevent it from being overwritten during the restore in case your restore is bad and a repair is necessary.
Recovery Storage Group (RSG)
If you plan to use an RSG in your disaster recovery plans, enough capacity will need to be available to handle all the databases you wish to be able to simultaneously restore on that server.
Backup to Disk
Many administrators perform a streaming online backup to a disk target. If your backup and restore design involves backup to disk, enough capacity needs to be available on the server to house this data. Depending on the backup type, this can be as small as the database and logs, to as large of a backup set that you require. For example, some organizations have enough capacity on the backup LUN to handle 2 full backups plus all the incremental in between.
Log Capacity
The transaction log files are a record of every transaction performed by the ESE database engine. All transactions are written to the log first and then lazily written to the database. Unlike previous versions of Exchange, in Exchange 2007 the transaction logs have been reduced in size from 5MB to 1MB. The total capacity of the logs will not change, as there will be five times as many log files. This change was made to support the continuous replication features, and to minimize the amount of data loss if the primary storage fails.
The following table can be used to estimate the number of transaction logs that will be generated (per day) on an Exchange 2007 mailbox server when the average message size is 50KB:
|
Mailbox Type
|
Message Profile
|
Logs Generated / Mailbox
|
|
Light
|
5 sent/20 received
|
7
|
|
Average
|
10 sent/40 received
|
14
|
|
Heavy
|
20 sent/80 received
|
28
|
|
Very Heavy
|
30 sent/120 received
|
42
|
The following guidelines have been established for how message size affects log generation rate:
- If the average message size doubles to 100K, then the logs generated / mailbox increases by a factor of 1.9 (when compared with an average message size of 50KB). This number is the percentage of the database that is the attachments and message tables (message bodies and attachments).
- Thereafter, as message size doubles, the impact to the log generation rate per mailbox also doubles.
For example:
- If you have a message profile of Heavy and an average message size of 100KB, then the logs generated / mailbox would be 28 * 1.9 = 53.
- If you have a message profile of Heavy and an average message size of 200KB, then the logs generated / mailbox would be 28 * 3.8 = 109.
Backup and Restore Factors
Most enterprises that perform a nightly full or incremental backup will allocate the capacity of about 3 days worth of log files in a storage group on the transaction log LUN because the transaction logs will be truncated each night. If backup has a problem, you don't want to fill up the log drive, which would dismount the databases in the storage group(s). However, there are a few other considerations to the log LUN size. If the backup and restore design allows you to go back 2 weeks and roll forward all the logs since then, you will need two week's worth of log file space.
If the backup design includes weekly full and daily differential backups, then the log LUN would need to be larger than an entire week's worth of logs to allow both backup and replay during restore. If the backup design includes a weekly full and daily incremental backup, the log LUN would also need to be larger than all the logs in every incremental backup in your backup set to allow replay during restore.
Move Mailbox
Moving mailboxes is a primary capacity factor for large mailbox deployments. Most large companies move a percentage of their users on a nightly or weekly basis to different databases, servers, or sites. It may also be necessary to over provision the log LUN to accommodate user migration to Exchange 2007. While the source Exchange server will log the record deletions, which are small, it is the target server which must write everything transferred to the transaction logs first. If you generate 10GB of log files in one day, and keep a 3 day buffer of 30GB, then moving fifty 2GB mailboxes (100GB), would fill up your target log LUN and cause downtime. In cases such as these, you may have to allocate additional capacity for the log LUNs to accommodate your move mailbox practices.
Log Growth Factor
For most deployments we recommend that you add an overhead factor (aka "fluff factor") of 20% to the log size (after all other factors have been considered) when creating the log LUN to ensure necessary capacity exists in moments of unexpected log generation.
Example
Step 1: Database Size
Let's start with a 1GB mailbox with a goal of housing 4,000 very-heavy message profile mailboxes on a clustered mailbox server that is in a CCR environment. Assuming a 50KB, average message size, these mailboxes receive an average of 52MB of mail per week.
|
Mailbox Size
|
Dumpster Size (2 weeks)
|
Whitespace
|
Total Size on Disk
|
|
1GB
|
104MB (2x52MB)
|
10MB
|
1.11GB (+11%)
|
Each user will consume 1.11GB of disk space. With CCR the database size should be under 200GB, so we could only house 180 mailboxes per database at the maximum. With 4000 mailboxes, we would need 23 databases, each on their own storage group, to house them. 23 databases divided into 4000 mailboxes for a final mailbox per storage group number of 174.
|
Mailboxes / DB
|
Total Databases
|
Database Size
|
|
174
|
23
|
193GB
|
Step 2: Transaction Log Size
The transaction log LUN should be large enough to accommodate all the logs you will generate during the backup set. Many organizations that utilize a daily full strategy plan for three times the daily log generation rate in the event that backup fails. When using a weekly full and then differential or incremental backup, at least a week's worth of log capacity is required to handle the restore case. Knowing that a very heavy message profile mailbox on average generates 42 transaction logs per day, a 4000 mailbox server will generate 168,000 transaction logs each day. This can be broken down by storage group to mean that each storage group will generate 7304 logs. 10% of the mailboxes are moved per week on one day (Saturday), and we perform a weekly full and daily incremental backup. In addition, the server can tolerate 3 days without log truncation.
|
Logs per SG
|
Log File Size
|
Daily Log Size
|
Move Mailbox Size
|
Incremental Restore Size
|
Log LUN Size
|
|
7304
|
1MB
|
7.13GB
|
17GB (17*1GB)
|
21.4GB
(3*7.13GB)
|
46GB
((17.4+21.4)*1.2)
|
The transaction log LUN needs to be large enough to handle both the logs generated by the move mailbox and have enough space to restore an entire week's worth of logs.
Transactional I/O
Transactional I/O is caused by end users performing actions on the Exchange server. Retrieving, receiving, sending, and deleting items causes disk I/O. The database I/O is 8KB in size and random, though it can be a multiple of 8KB when the I/O can be coalesced. Outlook users that are not using Cached Mode Outlook are directly affected by poor server disk latency and this is one of the most important concerns in storage design. To prevent a poor user experience, Exchange storage has specific latency requirements for database and transaction log LUNs. The transaction log LUN should be placed on the fastest storage with a goal of less than ten millisecond (<10ms) writes. The database LUN requires read and write response times of less than twenty milliseconds (<20ms).
Understanding IOPS
How do you determine your mailbox profile, or mailbox IOPS (Database I/O per mailbox, per second)? One of the key metrics when sizing storage in Exchange 2003 is the amount of database I/O per second each mailbox consumed. In Optimizing Storage for Exchange Server 2003, we show you how to measure your mailbox IOPS. Essentially, take the amount of I/O (both reads and writes) on the database LUN for a storage group, and divide that by the number of mailboxes in that storage group. 1000 mailboxes causing 1000 I/Os on the database LUN means you have an IOPS of 1.0 per mailbox.
Measure Baseline IOPS
Now that you know how IOPS are determined, measure your Exchange 2000/2003 baseline. Exchange 2007 will affect your baseline in a couple of ways. The number of mailboxes on the server will affect the overall database cache per mailbox. The amount of RAM influences how large your database cache can grow, and a larger database cache results in more cache read hits, thereby reducing your database read I/O. The key is that knowing your IOPS on a particular server is not enough to plan out an entire enterprise, since each server's RAM and number of mailboxes and storage groups will likely be different. Once you have your actual IOPS numbers, always apply a 20% I/O growth factor to your calculations to add some head room. You don't want a poor user experience because activity is a little heavier than normal, or because your RAID array just lost a disk.
Database cache
A 64-bit Windows Server running the 64-bit version of Exchange 2007 really opens up the amount of virtual address space. Exchange can now break through the 900MB database cache barrier to significantly reduce database read I/O and enable up to 50 databases per server. If Exchange can get a read hit in the database cache, it does not have to go to disk. This has the potential to reduce your database read I/Os significantly. The database read reduction is going to be dependent upon the amount of database cache that the Exchange server has available to it and the user message profile. Guidance on memory and storage groups can be found in Planning processor and Memory Configurations. Following this guidance will help you maximize the transactional I/O reduction over Exchange 2003. The amount of database cache per user is a key factor in the actual I/O reduction.
The following table demonstrates the increase is actual database cache per user when comparing the default 900MB in Exchange 2003, versus 5MB of database cache per user in Exchange 2007. It is this additional database cache that enables more read hits in cache, thus reducing database reads at the disk level.
|
Mailbox Count
|
E2003 DB Cache/Mailbox (MB)
|
E2007 DB Cache/Mailbox (MB)
|
DB Cache Increase over E2003
|
|
4000
|
0.225
|
5
|
23x
|
|
2000
|
0.45
|
5
|
11x
|
|
1000
|
0.9
|
5
|
6x
|
|
500
|
1.8
|
5
|
3x
|
Predict Exchange 2007 Baseline IOPS
The two largest factors that can be used to predict Exchange 2007 database IOPS is the amount of database cache per user and the number of messages each user sends and receives per day. This is based on the standard knowledge worker, that uses Outlook 2007 in cached mode, and has been tested to be accurate within +/- 20%. Other client types and usage scenarios may yield inaccurate results. The predictions are only valid for user database cache sizes between 2-5MB. The formula has not been validated with users sending and receiving over 150 messages per day. The average message size for formula validation was 50KB, but the message size is not a primary factor for IOPS.
|
User type (usage profile)
|
Send/receive per day approximately 50-kilobyte (KB) message size
|
DB cache per User
|
Estimated IOPS per user
|
|
Light
|
5 sent/20 received
|
2MB
|
0.08
|
|
Average
|
10 sent/40 received
|
3.5MB
|
0.16
|
|
Heavy
|
20 sent/80 received
|
5MB
|
0.32
|
|
Very heavy
|
30 sent/120 received
|
5MB
|
0.48
|
To estimate database cache size subtract 2048MB (3072MB with LCR) from the total amount of memory installed in the Exchange Server, and divide that amount by the number of users. For example, an Exchange Server with 3000 users and 16GB of RAM would deduct 2GB for the system, leaving 14GB of RAM, or 4.77MB per user (14GB/3000=4.77MB). If the average per user database cache size is 4.77MB and the average number of messages sent and received per day is 60 we can estimate both database reads and writes.
Database Reads
First we take the 60 messages per day and multiply it by .0048 resulting in .288.
Next we take the amount of database cache per mailbox (4.77MB) to the -.65th power. (5^-.65) resulting in .3622. Finally we multiply the 2 results to estimate our database reads per user of .104 (.288*.3622=.104).
Database Writes
For writes take the number of messages per user of 60 and multiply it by .00152 resulting in .0912 database writes per user.
The total database IOPS per user would be the addition of both reads and writes at .195 IOPS.
The formula would be ((.0048*M)*(D^-.65))+(.00152*M), where M is the number of messages and D is the database cache, per user. ((.0048*60)*(4.77^-.65))+(.00152*60) = .195
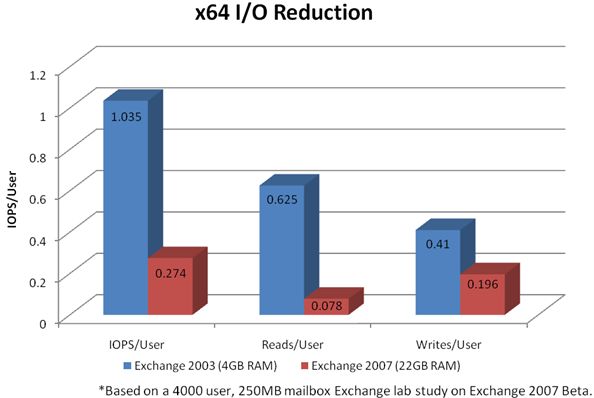
The following graph demonstrates the databases read and write reduction achieved when running Exchange 2007 with 4000 - 250MB mailboxes simulating Outlook 2007 in cached mode and the recommended server memory:
Effect of Online Mode Clients
Unlike cached mode clients, all online mode client operations occur against the database. As a result, read I/O operations will increase against the database. Therefore, the following guidelines have been established if the majority of clients will operate in online mode:
-
250MB online mode mailbox clients will increase database read operations by a factor of 1.5 when compared with cached mode clients. Below 250MB, the impact is negligible.
-
As mailbox size doubles, the database read IOPS will also double (assuming equal item distribution between key folders remains the same).
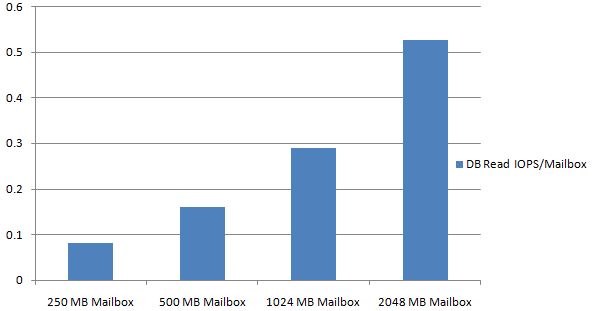 Testing has also shown that increasing the database cache beyond 5MB/mailbox will not significantly reduce the database read I/O requirements. The following graph depicts 2GB mailboxes using online mode clients and the effect increasing the cache beyond 5MB has on reducing the database read I/O requirements.
Testing has also shown that increasing the database cache beyond 5MB/mailbox will not significantly reduce the database read I/O requirements. The following graph depicts 2GB mailboxes using online mode clients and the effect increasing the cache beyond 5MB has on reducing the database read I/O requirements.
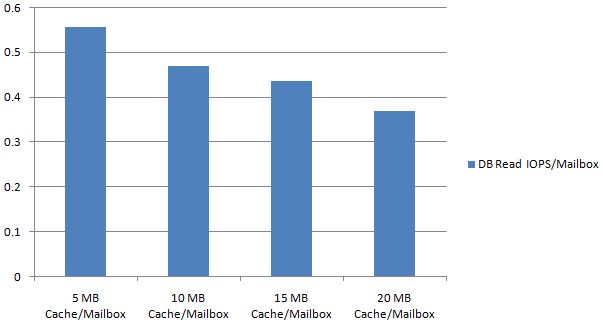 As a result of this data, two recommendations can be made:
As a result of this data, two recommendations can be made:
- Deploy cached mode clients where appropriate (see the "Mailbox Size (Item Count per Folder)" section for more information.
- Ensure that the I/O requirements are taken into consideration when designing the database storage.
For additional IOPS factors, such as 3rd party clients, see Optimizing Storage for Exchange Server 2003.
Database Read & Write ratios
In Exchange 2003, the database read to write ratio is typically 2:1 or 66% reads. With Exchange 2007, the larger database cache decreases the number of reads to the database on disk causing the reads to shrink as a percentage of total I/O. If you follow our recommended memory guidelines and use Outlook in cached mode, the read-to-write ratio should be closer to 1:1, which is 50% or less reads. When using Outlook in Online mode, or when using desktop search engines that do not utilize the Exchange 2007 Content Indexing Service, the read-to-write ratio will increase depending on the mailbox size (more read I/Os than write I/Os). Having more writes as a percentage of total I/O has particular implications when choosing a RAID type that has significant costs associated with writes, such as RAID5 or RAID6. Many third party applications and hand held devices perform many reads against the database impacting the database read to write ratio.
Log to DB ratio
In Exchange 2003, a transaction log LUN for a storage group requires roughly 10% as many I/Os as the databases in the storage group. For example if the database LUN is using 1000 I/Os, the log LUN would use approximately 100 I/Os. With the reduction in database reads in Exchange 2007, combined with the smaller log file size and the ability to have more storage groups, the log-to-database write ratio is roughly 1:2. For example, if the database LUN is consuming 500 write I/Os, you could expect your log LUN to consume approximately 250 write I/Os. After measuring or predicting the transactional log I/O, apply a 20% I/O overhead factor to ensure adequate headroom for busier than normal periods or hardware failure.
When using continuous replication, the primary transaction logs must be read and sent to the passive LUN. This overhead is an additional 10% in log reads. If the transaction log for a storage group, is consuming 250 write I/Os, you could expect an additional 25 read I/Os when using continuous replication.
For other factors that impact log I/O see Optimizing Storage for Exchange Server 2003.
Mailbox Size (Item Count per Folder)
In the Optimizing Storage for Exchange Server 2003 we explain how it is not the database size per se, but the number of items in your critical folders, as well as the client type that can cause a disk performance impact. This becomes more important as mailbox size increases.
Outlook 2007 in Cached Mode is important for reducing server I/O as much as 70% over Exchange 2003. The initial mailbox sync is an expensive operation, but over time, as the mailbox size grows, the disk subsystem burden is shifted from the Exchange server to the Outlook client. This means that having a large number of items in a user's Inbox, or an end-user searching a mailbox will have little effect on the server. This also means that Cached Mode users with large mailboxes may need faster computers than those with small mailboxes (depending on the individual user threshold for acceptable performance).
Outlook 2007 Cached Mode Recommendations (Client PC):
|
Mailbox Size
|
Memory Size
|
Hard Disk Speed
|
|
1GB
|
1GB
|
5400RPM
|
|
|
2GB
|
1-2GB
|
7200RPM
|
|
|
>2GB
|
Reduce mailbox size, or use online mode.
Your mileage may vary based on your specific hardware and performance threshold.
|
Note: If using Outlook 2007 RTM in Cached Mode, please download and install http://support.microsoft.com/kb/933493.
Both OWA and Outlook in Online mode store indices on and search against the server's copy of the data. For moderately sized mailboxes, this results in approximately double the IOPS per mailbox of a comparably sized Cached Mode client. The IOPS per mailbox for very large mailboxes is even higher. The first time you sort in a new way, such as by size, an index is created, causing many read I/Os to the database LUN. Subsequent sorts on an active index are very inexpensive.
The scenario that is rather painful is when a user has gone beyond the number of indices that Exchange will store, which for both Exchange 2003 and Exchange 2007, is 11 indices. In this case, when the user chooses to sort a new way, thereby creating a 12th index, it causes additional disk I/O. Since the index is not stored, this disk I/O cost occurs every time that sort is performed. Because of the high I/O that can be generated in this scenario, we strongly recommended storing no more than 5,000 items in core folders, such as the Inbox and Sent Items folders. Creating more top level folders, or sub-folders underneath the Inbox and Sent Items folders, will greatly reduce the costs associated with this index creation, so long as the number of items in any one folder does not exceed 5,000.
For more details, see Optimizing Storage for Exchange Server 2003 and the blog, Recommended Mailbox Size Limits.
Non-Transactional I/O
Transactional I/O occurs in response to direct user action and message delivery. It usually has the highest priority, and is the focus for storage design. The reduction in transactional I/O makes non-transactional I/O more important. With large mailboxes, particularly in the case of the 2GB mailbox, many enterprises are not doubling the user capacity, but in some cases increasing it tenfold. One such example would be moving from 200MB to 2GB. When you have such a significant increase in the amount of data on disk, you must now consider and account for non-transaction I/O when planning your storage design.
Content Indexing (CI)
In Exchange 2007, messages are indexed as they are received, causing very little disk I/O overhead (around 5%). Searching against the index is roughly 30 times faster than in Exchange 2003, and greatly assists in managing a larger mailbox for online clients.
Message Records Management (MRM)
MRM is a new feature that helps administrators and users manage their mail. Policies can be set to move or delete mail that meets specific thresholds, such as age. MRM is a scheduled crawl that runs against the database in a synchronous read operation similar to backup and online maintenance. The disk cost of MRM depends upon the number of items requiring action (e.g., delete or move).
We recommend that MRM not run at the same time as either backup or online maintenance. Our internal testing shows that MRM can crawl 100,000 items in 5 minutes! If you use continuous replication, you can offload VSS backups to the passive copy, allowing more time for online maintenance and MRM so that neither impact one another, nor affect end-users.
Online Maintenance
Many things occur when the database runs online maintenance (OLM), such as permanently removing deleted items and performing online defragmentation of the database. Maintenance causes reads, while online defragmentation causes both reads and writes. The amount of time it takes to complete maintenance is proportional to the size of the database and can be a limiting factor on how large databases are allowed to grow. For more information on OLM, see the blog Store Background Processes Part I.
Backup and Restore
There are many different methods available to the Exchange administrator when it comes to backup and restore. The key metric with backup and restore is the throughput, or the number of megabytes per second that can be copied to and from your production LUNs. Once you determine the throughput, you need to decide if it is sufficient to meet your backup and restore SLA. For example, if you need to be able to complete the backup within 4 hours, you may have to add more hardware to achieve it.
Depending on your hardware configuration, there may be gains that can be achieved by changing the allocation unit size. This can help with both streaming online backups, and the eseutil integrity check that occurs during a VSS backup. See the LUN Optimization section for more details.
Many administrators are not accustomed to having to deal with very large amounts of data on a single Exchange server. Consider a server with two thousand 2GB mailboxes. With the overhead described above, this is more than 4TB of data. Assuming you can achieve a backup rate of 175GB/hour (48MB/second), it would take at least 23 hours to backup this Exchange server. An alternative for servers that a fast recovery mechanism such as LCR or CCR might be to perform a full backup of 1/7th of the databases each day, and an incremental backup on the remainder. The full plus incremental strategy is the secondary recovery mechanism, so the additional time to restore the full plus all incremental backups may be an acceptable solution.
Example: (With 14 databases)
|
|
Day 1
|
Day 2
|
Day 3
|
Day 4
|
Day 5
|
Day 6
|
Day 7
|
|
Full
|
SG 1&2
|
SG 3&4
|
SG 5&6
|
SG 7&8
|
SG 9&10
|
SG 11&12
|
SG 13&14
|
|
Incremental
|
SG 3-14
|
SG 1&2 SG 5-14
|
SG 1-4 SG 7-14
|
SG 1-6 SG 9-14
|
SG 1-8 SG 11-14
|
SG 1-10 SG 13&14
|
SG 1-12
|
This backup strategy could complete in 3.7 hours, assuming a rate of 175GB/hour. Some solutions can achieve more or less throughput; however large mailboxes may require different approaches. With LCR & CCR, the passive copy is the first line of defense. You would only restore from backup if both the active copy and the passive copy fail or are otherwise unavailable. Recovering multiple days of incremental logs can add to the length of time it takes to recover. For this reason, incremental backup is usually only considered on a fast recovery solution, such as CCR or VSS clones. With a VSS clone, the recovery of the data is very fast, and adding a little time to replay logs may be acceptable in order to keep backup times within the backup SLA.
Streaming Online Backup
With streaming backups, it is recommended to separate streaming I/O (source and target) so that multiple storage groups being backed up concurrently do not compete for the same disk resources. Whether the target is disk or tape, there will be a throughput limit on the physical disks and controllers unique to each hardware solution. It may be necessary to isolate some storage groups from each other to maximize the number of concurrent backup operations, and throughput in order to minimize the size of the backup window.
Example: (With 14 databases)
|
|
LUN 1
|
LUN 2
|
LUN 3
|
LUN 4
|
LUN 5
|
LUN 6
|
LUN 7
|
|
1st Backup
|
SG 1
|
SG 2
|
SG 3
|
SG 4
|
SG 5
|
SG 6
|
SG 7
|
|
2nd Backup
|
SG 8
|
SG 9
|
SG 10
|
SG 11
|
SG 12
|
SG 13
|
SG 14
|
You can run streaming backups concurrently, one from each LUN, if you isolate your storage group LUNs from each other. The backup jobs should complete on the first storage group on each LUN before the second storage group begins to backup, isolating the backup streams. Two streaming backup jobs on the same physical disks may not be twice as fast, but it should be faster than a single streaming backup job with regard to the megabytes per second.
VSS Backup
Exchange 2007 uses the Volume ShadowCopy Service (VSS) included in Windows 2003 to take volume shadow copies of Exchange Server 2007 databases and transaction log files. For the basics on VSS, including both clone and snapshot techniques, I recommend that you read the whitepaper, Best Practices for Using Volume Shadow Copy Service with Exchange Server 2003.
The new feature in Exchange Server 2007 when using continuous replication, is the ability to run software VSS snapshot not just on the production copy, but on the passive copy. Taking a VSS snapshot on the passive copy removes the disk load on the production LUN during both the checksum integrity (eseutil), and subsequent copy to tape or disk. This also frees up more time on the production LUNs to run online maintenance, MRM, and other tasks.
Apply to the Hardware Design
Once you have your capacity, transactional, and non-transactional I/O requirements, you can apply them to a proposed hardware design. What kind of hardware is required for Exchange 2007? For processor and memory configurations see, Planning Processor and Memory Configurations. For storage, the transactional I/O requirements have been reduced, and with continuous replication, high availability no longer means having to use expensive Fibre Channel storage (though that is still a very good solution). All storage solutions must be listed on the Windows Server Catalog, and single copy cluster (SCC) solutions must have the entire solution on the Cluster Catalog.
One storage change is that Exchange 2007 does not support Network Attached Storage (NAS). But one danger when talking about storage is to pigeonhole a particular technology as being direct attached or a SAN. Most storage technologies can be either, so instead I'll attempt to describe storage best practices for both disk type and connectivity mechanism. The bottom line is that all storage is eventually presented as a LUN to the operating system. If the storage is properly tested and meets the storage requirements, it does not really matter how you connect to it or the actual type of disk. I'll discuss this in greater detail in the validation and monitoring section.
Storage Technology
The key aspects to choosing storage technology include; reliability, capacity, performance, complexity, manageability, and cost.
Serial ATA (SATA)
SATA is the serial interface for ATA/IDE drives which are typically found in desktop computers and is defined in detail on Wikipedia here: SATA. They are generally slower than SCSI and Fibre Channel disks, but they do come in large sizes. There are two classes of SATA drives enterprise and non-enterprise.
Non-enterprise SATA drives have slower RPM speeds, and are not designed for uninterrupted 24x7 loads. These drives work best for part time use, such as a backup to disk target.
Enterprise or full duty cycle physical disks are good for transactional I/O and are designed to run at peak load, 24x7. Disks with a faster rotational speed, such as 10K RPM disks, may be needed to meet your transactional I/O requirements.
Serial Attached SCSI (SAS)
SAS storage utilizes enterprise-class, high-performance hard disks and is defined in detail on Wikipedia here: SAS. The throughput on many SAS arrays far surpasses both SATA and traditional SCSI (up to 3Gbit/sec per drive or channel) and may help to meet your SLA for maintenance or backup (streaming performance). SAS arrays can be directly attached to the server and the cabling is simple. Smaller form factor SAS disks come in smaller capacities, yet they are extremely fast, and are ideal for Exchange 2003 deployments where the fastest speeds are necessary with smaller mailboxes. It is important to balance the disk speed with the I/O requirements. In many large mailbox deployments, 10K RPM SAS disks may be fast enough when you balance the capacity and I/O needs.
iSCSI
iSCSI or Internet SCSI is defined in detail on Wikipedia here: iSCSI. While iSCSI does connect a server to storage over Ethernet, it is important to treat it as your storage connection, and completely isolate your iSCSI storage network from all other network traffic. If available, options such as flow control, quality of service, and jumbo frames can further increase performance. The Microsoft iSCSI Initiator 2.0 and later supports MPIO, and in our test labs we have pushed over 250MB/second over 3 network cards, proving iSCSI as a capable storage transport for scenarios where high throughput is required.
Fibre Channel
Fibre Channel is a network technology often using fibre optic cables in storage area networks. For more information on Fibre Channel see the Wikipedia article here: Fibre Channel. It is a multi-gigabit speed network that is high performing, and excellent for storage consolidation and management. Check with your storage vendor for optimal configuration settings, as each storage vendor has recommendations that should be followed for the Queue Depth, Queue Target, or Execution Throttle settings on the HBA.
RAID Selection
Adding redundancy to your storage design is critical to achieve high availability. Redundant Array of Inexpensive Disks (RAID) behind a battery-backed controller is highly recommended for all Exchange servers and is detailed in this Wikipedia post: RAID. There are many RAID types, and many proprietary modifications to the known RAID types. I'm going to focus on the three most common types used in a server environment; RAID10, RAID5, and RAID6. Selecting a RAID type is a balance of capacity and transactional I/O. Mailbox size has a large impact on capacity, while smaller form factor disks impact performance.
RAID10
RAID10 is where you stripe (RAID0) mirrored (RAID1) sets. RAID0-1 is not the same as RAID10 and is not recommended for Exchange data. Transactional performance with RAID10 is very good, as either disk in the mirror can respond to read requests. No parity information needs to be calculated so disk writes are efficiently handled; each disk in the mirrored set must perform the same write.
When a disk fails in a RAID10 array, writes are not impacted because there is still a member of the mirror that can accept writes. Reads are moderately affected because now only 1 physical disk can respond to read requests. When the failed disk is replaced, the mirror is re-established, and the data must be copied or rebuilt.
RAID5
RAID5 involves calculating parity that can be used with surviving member data to recreate the data on a failed disk. Writing to a RAID5 array causes up to 4 I/Os for each I/O to be written, and the parity calculation can consume controller or server resources. Transactional performance with RAID5 can still be good, particularly when using a storage controller to calculate the parity. However, some array controllers can halve the total amount of write I/O when writing a large I/O that encompasses the stripe size.
When a disk fails in a RAID5 array, the array is in a degraded state and performance is less and latencies are higher. This is because most arrays spread the parity information equally across all disks in the array and it can be combined with surviving data blocks to reconstruct data on the fly. Both reads and writes must access multiple physical disks to reconstruct data on a lost disk, thereby increasing latency and reducing performance on a RAID5 array during a failure. When the failed disk is replaced, the parity and surviving blocks are used to reconstruct the lost data, which is a painful process that can take hours or days. Should a second member of the RAID5 array fail during the Interim Data Recovery Mode or rebuild, the RAID group is lost. Because of this vulnerability, RAID6 was created.
RAID6
RAID6 adds an additional parity block and provides roughly double the data protection over RAID5, but at a cost of even lower write performance. As physical disks grow larger, and consequently RAID rebuild times grow longer, in some cases RAID6 is necessary to prevent LUN failure should an uncorrectable error occur during the rebuild, or should a 2nd disk in the array group fail during rebuild. Due to disk capacity, some vendors support RAID6 instead of RAID5.
|
|
Speed
|
Capacity Utilization
|
Rebuild Performance
|
Disk Failure Performance
|
|
RAID10
|
Best
|
Poor
|
Best
|
Best
|
|
RAID5
|
Good
|
Best
|
Poor
|
Poor
|
|
RAID6
|
Poor
|
Good
|
Poor
|
Poor
|
Transaction Logs
Transaction logs are the most important data set and good write latency is critical for server performance. Logs should be placed on RAID1/RAID10 arrays with battery-backed write cache. For more information on the importance of quick, low latency storage for the transaction logs see Optimizing Storage for Exchange Server 2003 (http://go.microsoft.com/fwlink/?LinkId=49324).
Databases
RAID10 is the ideal configuration for Exchange, and it works well with large capacity disks.
With Exchange 2003, RAID5 provides the best capacity efficiency, though its poorer performance seldom allows the extra space to be utilized. In many Exchange 2003 deployments, more physical disks are required to meet the transactional performance requirements of RAID5 than with RAID10. With Exchange 2007, the shift of increasing database writes as a percentage of the database I/O causes RAID5 LUNs to perform worse than with Exchange 2003. However, when following the recommendations to achieve up to transactional I/O reduction, RAID5 may be a good solution.
RAID5 is useful for utilizing high speed, smaller capacity disks. In large mailbox solutions RAID5 may be able to provide more transactional performance than you need to meet the capacity requirements with less physical disks than RAID10. Rebuild performance can have a significant impact on storage throughput.
- Depending upon the storage array and configuration, this impact may cut storage throughput in half.
- Scheduling rebuilds outside of production hours can offset this performance hit while sacrificing reliability.
- With CCR, you can move to the alternate node so rebuild does not impact production users.
- If neither option is available, then additional I/O throughput should be designed in to the architecture to accommodate rebuild conditions with RAID5/RAID6 during production hours. This additional I/O throughput can be up to twice the non-failed state I/O requirements.
RAID6 arrays do not perform as well as RAID5 and is also impacted by rebuild performance. Follow the RAID5 guidance for ensuring enough I/O throughput for RAID6 arrays.
LUN Design
In many cases the physical disk, or logical unit number (LUN), that the operating systems recognizes, is abstracted from the physical hardware that is actually behind that "disk". Refer back to the capacity section and be sure to allocate additional space for maintenance, the recovery storage group, and database restoration.
It has always been critical to separate transaction logs from the database at both the LUN and physical disk level for performance and recoverability purposes. On all storage arrays, mixing random and sequential I/O on the same physical disks can reduce performance. From a recoverability perspective, separating a storage group's transaction logs and databases ensure that a catastrophic failure of a particular set of physical disks will not cause a loss of both database and transaction logs.
Exchange database I/O is very random and most storage subsystems benefit when the physical disks are performing the same workload which is why we recommend that you dedicate physical spindles to Exchange workloads. Many storage arrays virtualize the storage so that many physical disks are first pooled into a group of disks and then LUNs are carved out of the available space in that disk group and distributed equally across every physical disk. When not using continuous replication, it is perfectly acceptable for the physical disks that are backing a storage group's database LUN to also back other LUNs that house the databases for other storage groups and servers. Likewise it is not critical to isolate each storage group's transaction log LUN onto separate physical spindles, even though the loss of sequential I/O will slightly impact performance. It is important to separate the log and database LUNs from the same storage group onto separate physical disks. It is not realistic to dedicate two or four, 500GB physical disks to a single storage group's transaction log LUN if you require 100 IOPS and 5% of the capacity.
There are nearly an infinite number of ways to design the LUNs in Exchange 2007. We recommend these two designs to limit complexity.
2 LUNs per Storage Group
Creating 2 LUNs (log & db) for a storage group is the standard best practice for Exchange 2003. With Exchange 2007, in the maximum case of 50 storage groups, the number of LUNs you provision will depend upon your backup strategy. If your recovery time objective (RTO) is very small, or if you use VSS clones for fast recovery, it may be best to place each storage group on its own transaction log LUN and database LUN. Because doing this will exceed the number of available drive letters, volume mount points must be used.
Some of the benefits of this strategy include:
- Enables hardware-based VSS at a storage group level, providing single storage group backup and restore.
- Flexibility to isolate the performance between storage groups when not sharing spindles between LUNs.
- Increased reliability. A capacity or corruption problem on a single LUN will only impact one storage group.
Some of the concerns with this strategy include:
- 50 storage groups using continuous replication could require 200 LUNs which would exceed some storage array maximums. CCR solutions could have 100 LUNs on each node, while LCR could have all 200 LUNs presented to a single server.
- A separate LUN for each storage group causes more LUNs per server increasing the administrative costs and complexity.
2 LUNs per Backup Set
A backup set is the number of databases that are fully backed up in a night. A solution that performs a full backup on 1/7th of the databases nightly could reduce complexity by placing all of the storage groups to be backed up on the same log and db LUN. This can reduce the number of LUNs on the server.
Some of the benefits of this strategy include:
- Simplified storage administration. Fewer LUNs to manage.
- Potentially reduce the number of backup jobs.
Some of the concerns with this strategy include:
- Limits the ability to take hardware based VSS backup and restores.
- The 2TB limit on an MBR partition would limit how far this would scale in capacity. (See MBR vs. GPT)
- A capacity or corruption problem on a single LUN could impact more than one storage group.
Continuous Replication LUNs (CCR/LCR)
When using continuous replication, additional factors need to be taken into account when designing the storage LUNs, especially for storage that is shared between multiple CCR clusters. If the storage is not shared, it is still important to isolate the source and target LUNs from each other. See the Exchange 2007 documentation for more information on isolating the source and target LUNs. The passive LUNs in a continuous replication environment require two times the disk I/O as the active LUNs because the log replay is a significant generator of both read and write disk I/O. If the passive LUN becomes the active LUN in an environment with multiple clusters sharing the same storage, that LUN could suffer poor performance and high latencies, particularly if other passive LUNs are producing two times the I/O of the active LUNs. This behavior causes additional design considerations that I will summarize in two options; over-provisioning the LUN performance; or physically isolating the active and passive LUNs from other LUNs.
Physical Isolation
One option is to not share the storage of either the active or passive LUNs in a CCR cluster with other servers. If you do place more than one CCR cluster on this storage, configure each CCR node to have its own disk group that does not share physical disks within the storage array with other CCR clusters. Isolating the spindles for both active and passive LUNs in a CCR environment is an option so that the passive I/O, which is heavier and not as sensitive to latency, does not affect the active I/O. Both the source and target LUNs should be designed to meet the source I/O requirements. The CCR design is such that the target LUNs will use more I/Os with higher latencies than the source LUNs. The target LUNs will keep up with replication, and will improve efficiency as the disk latency grows which will allow it to keep up with the replication by sending more log files in each batch. For example, a CCR cluster would require 4 isolated disk groups. The active node would require LOG and Database LUNs, and the passive node would require LOG and Database LUNs with the source and target LUNs ideally on separate storage.
Over Provisioning
Another option is to provision all LUNs with two times the performance required by the source LUNs, because both the source and target LUNs need to handle the target load since either LUN could become the target. Provisioning the storage this way will double the transactional IOPS per mailbox calculation on a per server basis. The storage needs to be able to handle the two times I/O overhead of the passive so that the performance of the active is not affected.
Partition Design
A LUN that is visible in disk management can be further subdivided into multiple partitions. It is an Exchange best practice to create a single partition on a LUN for Exchange data.
MBR vs. GPT
When creating a partition on a data volume in Windows Server 2003 SP1 and all x64-based Windows platforms, a new partition type is available, GUID partition table (GPT). GPT allows larger than 2TB partitions, and up to 128 primary partitions. Replication and cyclical redundancy check (CRC) protection of the partition table adds a little reliability. GPT is not supported on boot or system volumes, and they are not supported as a shared disk in Windows clusters. For Exchange log and database LUNs that are not a shared disk in Windows cluster, it is a best practice to use MBR partitions. If you plan to have 2TB partitions, or plan to grow your partitions beyond 2TB in the near future, it is advisable to use GPT. It is also an Exchange best practice to use a single partition on a LUN that is properly aligned and formatted. For more information on GPT see Q284134.
Partition Alignment
Most partitions are misaligned when created using the Disk Management tool and should be created with diskpart instead. Aligning partitions to track boundaries can have performance benefits, depending on the storage. Always use the storage vendor's recommended setting, but if your storage vendor does not have a recommended setting, use 64 sectors or 32KB. See the diskpar(t) blog for more details.
Partition Allocation Unit Size
The Exchange product group has never offered specific guidance around NTFS allocation unit size in the past. Instead we have chosen to leave the decision around guidance in this area to storage vendors implementing solutions for Exchange Server. With the release of Exchange Server 2007 we are changing our direction on this subject. It is recommended that customers configure the NTFS volumes hosting their Exchange databases with an NTFS allocation unit size of 64KB. The recommendation of 64KB is based on the performance improvements seen with large sequential read operations. This type of profile is typically seen with streaming backup and eseutil tasks. It will not affect anything else. The benefits of a 64KB allocation unit size seen with large sequential read operations are also visible for Exchange 2003. Previous recommendations of 4KB (edb) and 8KB (stm) for Exchange 2003 are still valid for Exchange 2003, and they do not negatively affect the environment in any way. We do not recommend taking any action to change the NTFS allocation unit size for existing Exchange 2003 database drives that are currently configured to 4KB (edb) and 8KB (stm). The 64KB allocation unit size recommendation is only applicable as guidance for the creation of new volumes hosting Exchange 2003 and 2007 database files.
In some scenarios a benefit is seen with sequential I/O, particularly when performing a streaming backup, or when running eseutil for a VSS checksum integrity or database repair. Always use the storage vendor's recommended setting, but if your storage vendor does not have a recommended setting, use 64KB.
Testing has shown that changing the NTFS allocation size from 4KB to 64KB does not result in any improvement for transaction log sequential throughput, therefore you can utilize the default NTFS allocation size (4KB) for NTFS volumes hosting Exchange transaction logs.
Volume Mount Points
There are many cases, such as in multi-node single copy clusters, where more LUNs are needed than there are available driver letters. In those cases, you must use volume mount points. Drive letters are really a legacy DOS feature to recognize partitions or disks, and it is best to avoid using too many drive letters. It is much easier to place all transaction log and database LUNs on a volume mount point for ease of administration. If you have 20 storage groups, each with a database, it is difficult to remember which drive letter houses database 17. Below is an example on using volume mount points.
|
Transaction Logs (L:)
|
Databases (P:)
|
|
L:\SG1LOG
|
P:\SG1DB
|
|
L:\SG2LOG
|
P:\SG2DB
|
|
L:\SG3LOG
|
P:\SG3DB
|
|
L:\SG4LOG
|
P:\SG4DB
|
In this example L: and P: are anchor LUNs which house all the log and database LUNs respectively. Each folder on these drives, are a volume mount point to a separate LUN.
Hardware-based VSS
When using a hardware-based VSS, there are a few recommendations for placing Exchange data on the LUNs. For a hardware-based VSS solution, each transaction log LUN and database LUN should only house the files from the chosen backup set. If you want to restore a storage group without affecting any other storage group, then you will need a separate transaction log LUN and database LUN for each storage group. If you are willing to take other databases and storage group's offline to restore a single database, then you can place multiple storage groups on a single transaction log LUN and database LUN.
Software-based VSS
When using software-based VSS, particularly with large mailboxes and continuous replication, your backup is a two-step strategy. First, you take a VSS snapshot, run checksum integrity, and then you stream the flat files off to disk or tape. In my earlier example of using a 7-day cycle to run full and incremental backups, it may make sense to place all the storage groups in the same backup set on the same LUNs. For example, if you had 21 storage groups, you could place 3 storage groups on the same transaction log LUN and database LUN.
LUN Reliability
It is always important to place a storage group's transaction logs and databases on separate physical disks because doing so increases reliability. With continuous replication, it is also important to separate the active and passive LUNs on completely separate storage. With CCR and LCR you want storage resiliency in the event of a catastrophic failure of the primary storage.
LUN Example
Let's build upon the previous capacity example, and apply that information to the creation of the actual LUN where the backup frequency is a daily full. We want to enable content indexing, and we will place it on the Database LUN. 5% of 193GB is approximately 10GB. We will need to add this to our final LUN size.
The growth factor for 193GB should be 20% of the final database size. 20% of 193GB is 39GB.
|
Database Size
|
Growth Factor
|
Content Indexing
|
DB LUN Size
|
|
193GB
|
39GB
|
10GB
|
241GB
|
Each storage group creates 7.13GB of logs per day, and you want to house at least 3 days worth of logs.
|
SG Logs Daily
|
SG Logs 3 Days
|
Log LUN Size
|
|
7.13GB
|
21.4GB
|
25.7GB (21.4GB+20%)
|
Move Mailbox
Our example organization moves 10% of its mailboxes per week, and they do the moves on Saturday, so the log LUN must handle all of it on one day. A move mailbox strategy used for our Exchange servers at Microsoft is to distribute the incoming users equally across each of the storage groups. This means that our example server with 4000 users will move approximately 400 users each Saturday. With 23 storage groups, each storage group must receive seventeen 1GB mailboxes.
|
SG Logs 3 Days
|
SG Mailbox Moves
|
Log LUN Size
|
|
21.4GB
|
17.4GB (17-1GB Users)
|
46.6GB (38.8GB+20%)
|
With this layout you should never move more than 17 users to a storage group on a single day, so it may make more sense to increase the size log LUN further in case you need to move more than 10% on any particular day.
Storage Validation
Properly designing a storage solution for Exchange 2007 is the first step to a successful deployment. It is important to validate your storage solution configured exactly how you plan to deploy it before going into production. The following is guidance for successfully testing a storage solution, beginning with a program that includes solutions that have already been tested.
ESRP
The Exchange Solution Reviewed Program (ESRP) facilitates 3rd party storage testing and best practice solution publishing for Exchange. Since storage can be configured in many ways, evaluating tested configurations and leveraging best practices can reduce costs, and speed the time to deployment. Exchange 2007 solutions will be available shortly after RTM. Today, taking a good Exchange 2003 solution and validating it with the next version of Jetstress may show that only small changes will be required for success on Exchange 2007. An example would be to move to 300GB from 72GB physical disks.
Storage Testing
Before testing a solution, some legwork is required to understand what it is you are trying to achieve by testing. Some of the keys to successful storage testing include:
- Understand what success looks like. What performance, throughput, and capacity numbers do you need to hit?
- Test with as many servers attached to the storage as you will have in production. This includes non-Exchange servers and workloads, as well.
- Test with production sized databases, with the physical disk capacities filled to production level. Most physical disk performance characteristics will change based on the data set size.
- Determine that the storage meets the transactional I/O requirements, and determine the maximum performance of the solution within acceptable latencies.
- Determine that the storage meets the backup throughput and performance requirements to meet your backup and restore service level agreement (SLA)
Exchange Tools
Jetstress accurately simulates Exchange I/O characteristics, and it is quick and easy to use. It includes both a stress test and a performance test which show the maximum performance of a LUN within acceptable latencies. A new version of Jetstress is in progress to support Exchange 2007. Some of the new features include:
- Backup and Restore Functionality
- Wizard GUI interface similar to ExBPA
- Support for 50SG/50DB
- Engine redesign for better tuning
- Database creation and copy improvements
Load Generator, a replacement for Load Simulator is used for simulating Outlook 2003/2007 clients on Exchange 2000/2003/2007. Both tools simulate Outlook and require a fully configured Exchange 2007 environment for testing. Simulating Outlook clients is the only way to measure actual client latency (rather than just the server disk latency).
Exchange Stress and Performance Tool (ESP) is used to simulate Internet protocols such as; POP3, IMAP4, and SMTP. It is often used to simulate incoming MIME mail from the Internet to an organization.
Exchange 2007 Mailbox Server Role Storage Requirements Calculator can be used to help design the optimal storage layout by looking at the storage requirements (I/O performance and capacity) as well as other input factors.
Storage Monitoring
After you have designed, validated, and deployed a solution, you have just finished the prerequisites for a successful Exchange solution. I/O changes over time as mailboxes grow, as users move, and as habits change. Monitoring Exchange storage is critical to catch hardware and software warnings and error conditions before they lead to data corruption or downtime. Shared storage scenarios open up Exchange storage to other application I/O load and are very difficult to keep healthy.
On the Exchange Server, performance monitor is a window into storage health. RPC averaged latency should be under 50ms on average and RPC requests should be below 30 at all times. Disk latency should be under 10ms for log writes, and less than 20ms for database reads and writes.
Some other Microsoft tools that can help include:
1. Microsoft Operations Manager (MOM)
The Exchange management pack for MOM is a treasure trove of rules, alerts, and best practices that assist in increasing availability.
2. Exchange Best Practice Analyzer (ExBPA)
ExBPA, which also has a management pack for MOM, is a great tool to check that your Exchange organization is configured correctly and following the best practices.
3. Exchange Troubleshooting Assistant (ExTRA)
ExTRA programmatically executes a set of troubleshooting steps to identify the root cause of performance, mail flow, and database mounting issues. The tool automatically determines what set of data is required to troubleshoot the identified symptoms, and collects configuration data, performance counters, event logs and live tracing information from an Exchange server and other appropriate sources. The tool analyzes each subsystem to determine individual bottlenecks and component failures, and then aggregates the information to provide root cause analysis.
Exchange Performance Troubleshooting Analyzer (ExPTA)
ExPTA, now a subset of ExTRA, collects configuration data, performance counters, and live tracing information from an Exchange server. The tool analyzes each subsystem to determine individual bottlenecks and then aggregates the information to provide root cause analysis.
On most storage, there is a way to see performance metrics, and monitoring these metrics can catch performance issues early, before they bubble up to the Exchange Server. If available, MOM integration from the storage vendor can assist in making sometimes proprietary metrics easy to understand. Some of the general metrics to keep an eye on are:
- Disk Utilization Percentage
- How busy are the physical disks?
- Read Cache Hit Ratio
- How well is the storage controller cache being utilized?
- Write Pending Requests
- How often is the controller waiting for the physical disk?
- Storage Processor Utilization Percentage
- How busy is the storage CPU?
Summary
The goal is to reduce cost and complexity while enabling large mailboxes. The transactional I/O in Exchange 2007 has been greatly reduced, particularly database reads. CCR enables non-shared storage clustering & large mailboxes. Features such as content indexing and MRM help manage large mailboxes. Exchange 2007 storage solutions are different, yet the validation and monitoring is the same. It is no longer just about the IOPS per user. The number of users and storage groups on a server, as well as the amount of database cache (RAM) has a significant effect on server I/O. The capacity and the non-transactional I/O requirements must be balanced with the transactional I/O needs.
- Robert Quimbey