This article highlights the current limitations in offerings by FaaS providers for ML inference applications and how capabilities in Azure Functions overcome these making it an ideal platform for such applications. It also links to an end to end sample illustrating these features.
ML Inference in FaaS Services
The core promise of Serverless/FaaS (Functions as a Service) computing is to make it easier for developers to build, deploy and scale up their applications. Among the different kinds of applications - ML applications have seen an explosion in their usage and are now rapidly being deployed and bringing unprecedented novel capabilities in various domains.
A typical ML workflow consists of using sample data to train a model and then use that model in an application to make predictions based on input. These stages are typically called training and inference respectively. On the surface, ML inference should be a straightforward FaaS use case as essentially there is a single "predict" function that is called to "infer" the result for a particular input. However, due to various limits that typical FaaS platforms impose it hasn't been as optimum a platform that it can be. These are some of the limitations:
1. ML libraries can be big
ML(especially Deep learning) libraries can be big in size. For example the PyTorch (even the non-CUDA version) library is around ~300MB. However, most FaaS providers only allow a maximum of ~250MB-~500MB of deployed package size including any modules needed in the application. Customers have to resort to getting around to these limitations by compressing shared libraries, removing test folders etc.
2. Python ML libraries use native dependencies
Many Python ML libraries call into other C/C++ libraries, those need to be recompiled based on the OS causing a mismatch between the development and production deployments. For instance, developers using Windows have to resort to using Docker before deploying their FaaS application.
3. ML models can be big
Some of the latest ML models can be very big in size - for example the AlexNet pre-trained PyTorch model is 230MB. Some models like GPT-2 can be several GB in size. FaaS offerings have a limited deployment size package as mentioned above - further, they don't offer a way to separate out the model from the code by mounting a file system for instance.
Further, some large models need to be completely loaded into memory before they can be used and amount of memory offered in current FaaS offerings might not be enough.
4. Concurrency models for I/O bound invocations are sub-optimal
Many ML inference API's are typically I/O bound, however, in current FaaS execution frameworks a single instance cannot handle concurrent requests. The can lead to a lot of wasted idle resources on individual instances.
5. Cold start
FaaS workloads scale down to zero instances when not being used, therefore starting a new instance always incurs lag - which is called cold start. For many applications this lag is not acceptable.
6. GPU support is not available
Many inference applications have a very stringent latency requirements (think for instance applications related to providing auto-suggestions as you type). To meet these latency requirements often (especially for bigger models) GPU processing can lead to several times of improvement. However FaaS providers currently do not support GPU's.
7. No native support for long running ML workloads and/or orchestration patterns
Some ML workloads might be inherently long running and/or have complex orchestration needs. Current FaaS providers do not offer native frameworks for these scenarios and customers need to resort to external services and built the complex coordination logic themselves.
Azure Functions Python
In Azure Functions Python capabilities and features have been added to overcome some of the above limitations and make it a first class option for ML inference with all the traditional FaaS benefits of scaling on demand, fast iteration and pay-for-use.

1. Higher deployment package sizes
Azure Functions support higher deployment packages as much as several GB in size. This means that even larger deep learning frameworks like TensorFlow and PyTorch can be supported out of the box without resorting to having to reduce their size.
2. Support for Remote Build
As mentioned above, many Python libraries have native dependencies. This means if you are developing your application on Windows and then deploy it in production which typically is on Linux - it might not work as they have to be recompiled to work on another operating system.
To help with this problem in Azure Functions we built the Remote Build functionality, where we automatically compile and pull in the right libraries on the server side. Hence, they don't have to be included in your deployment package locally and only need to be referenced in your requirements.txt file. This is the default experience when using VSCode or the func core tools to deploy your Python Azure Functions application. This is a snippet from the deployment logs showing the libraries being installed on the server side.
12:02:54 AM pytorch-image-consumption: Starting deployment...
.
12:03:01 AM pytorch-image-consumption: Running pip install...
...
12:03:14 AM pytorch-image-consumption: [07:03:14+0000] Collecting torch==1.4.0+cpu
12:03:14 AM pytorch-image-consumption: [07:03:14+0000] Downloading https://download.pytorch.org/whl/cpu/torch-1.4.0%2Bcpu-cp37-cp37m-linux_x86_64.whl (127.2MB)
12:03:45 AM pytorch-image-consumption: [07:03:45+0000] Collecting torchvision==0.5.0
12:03:45 AM pytorch-image-consumption: [07:03:45+0000] Downloading https://files.pythonhosted.org/packages/1c/32/cb0e4c43cd717da50258887b088471568990b5a749784c465a8a1962e021/torchvision-0.5.0-cp37-cp37m-manylinux1_x86_64.whl (4.0MB)
....
12:04:08 AM pytorch-image-consumption: [07:04:08+0000] Successfully installed azure-functions-1.2.1 certifi-2020.4.5.1 chardet-3.0.4 idna-2.9 numpy-1.15.4 pillow-7.1.2 requests-2.23.0 six-1.14.0 torch-1.4.0+cpu torchvision-0.5.0 urllib3-1.25.9
3. Support for mounting an external file system through Azure Files
To allow for arbitrarily large ML models and to separate the workflow of building the application and training your ML model the capability to automatically mount a configured Azure file share has been recently introduced.
This is as simple as using an Azure CLI command where the $shareName Azure File share will automatically be mounted whenever the $functionAppName Function app starts up. The path available to the Function app will be with the name of $mountPath.
az webapp config storage-account add \
--resource-group myResourceGroup \
--name $functionAppName \
--custom-id $shareId \
--storage-type AzureFiles \
--share-name $shareName \
--account-name $AZURE_STORAGE_ACCOUNT \
--mount-path $mountPath \
--access-key $AZURE_STORAGE_KEY
This is an Azure Files storage view with two different models.
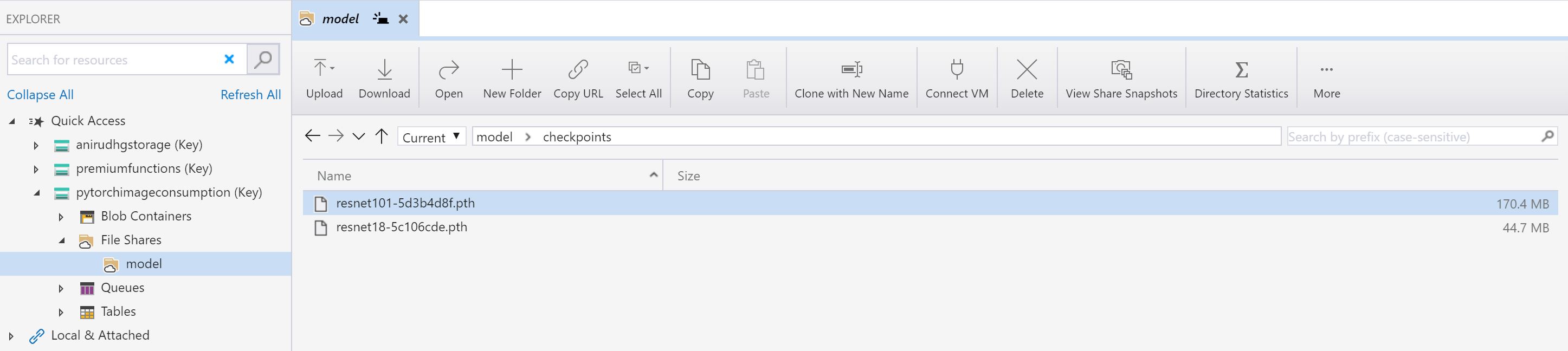
This functionality is available both in the Consumption and Premium plans. It is also worth noting that Azure Files have a Premium tier which can be used as well - it offers a higher level of performance i.e. high throughput and low latency for IO-intensive workloads(many ML applications)
The above two features Remote Build and support for Azure Files allow the deployment package to be much smaller. For example, in the PyTorch sample referenced below the total package size would have been close to 520MB in size when using the resnet100 model (~350MB for PyTorch and ~170MB for the model) while without it it is barely 50KB in size.
4. Azure Functions concurrency model is optimal for I/O bound invocations
In Azure Functions - the same instance is re-used for concurrent calls. This can lead to optimum use of resources especially for concurrent I/O bound invocations where the underlying api has async variants.
5. Azure Functions Premium SKU's offer higher memory limits and no cold start
The Azure Functions Premium SKU offers higher memory limits - up to 14GB for cases where you would want to load the entire model in memory.
| SKU | Cores | Memory | Storage |
|---|---|---|---|
| EP1 | 1 | 3.5GB | 250GB |
| EP2 | 2 | 7GB | 250GB |
| EP3 | 4 | 14GB | 250GB |
It also avoids cold start for those applications where there cannot be any latency at all.
Further, the custom container support enables integration with the Azure Machine Learning service such that you can package a model from the Azure ML service into an Azure Function Premium app and allows the use of a Conda environment.
6. Deploy Azure Functions to a Kubernetes cluster with GPU support
Finally, as in Azure Functions the programming model is separate from the deployment target, an Azure Function app can be deployed to a Kubernetes cluster (it can be scaled up and down using KEDA). Many managed Kubernetes offering (including AKS) have GPU support.
7. Orchestrating inference invocations - Durable Functions Python
With the impending release of Durable Functions Python long running ML workloads can now be supported. Durable Functions allows many different orchestration use cases including processing multiple inputs in a batch, parallelizing classification tasks etc. These are enabled by the Chaining, Fan-Out Fan-In and other Durable Function patterns. This sample illustrates the use of the Fan-Out Fan-In pattern doing parallel image classification using TensorFlow.
Sample
To put this all together and show a real end to end example - please find a step by step walk through example of an Azure Function app which shows how these pre-trained PyTorch models can be loaded from an Azure File share in an ML inference application which classifies images.

It illustrates the use of Remote Build, gives guidance on how you can deploy the same app to the Premium plan for no-cold start and higher memory limits and gives guidance on how the same app can be deployed to a AKS cluster with GPU. More end to end examples will be added soon for text generation and other ML tasks.
Hopefully this blog post encourages you to consider Azure Functions for your ML inference applications. Please ask any questions in the comments, or open any issues in the Azure Functions Python Worker repo or in the sample repo.
 Microsoft
Microsoft