Hi cluster fans,
In Windows Server 2008 R2 Failover Clustering we have incorporated a significant architectural innovation called Cluster Shared Volumes (CSV), which functions as a distributed-access file system optimized for Hyper-V. This means that any node in a cluster can access the shared storage and any node can host VMs, regardless of which node “owns” the storage. This behavior was not included in Windows Server 2008 and this blog will discuss CSV in more detail. For information about configuring and deploying CSV, please check out this guide and be sure to send us your feedback!
Disk Ownership in 2008 and Earlier
In Windows Server 2008 and earlier, one of the required resources for each resource group was a “physical disk resource”. Basically this physical disk resource managed the cluster’s access to the application’s data on the shared storage device. This was to ensure that, at most, one node could access the data at any time to avoid corruption of the data on the LUN. If you had multiple nodes writing data to that same disk at the same time you would risk corruption. In Windows Server 2008, ownership of disks was determined by a SCSI SPC-3 protocol called ‘Persistent Reservations’ (PRs). When one node “owned” a disk, it would place a reservation on that volume. If another node tried to access this disk, it would ask for ownership of the PR, which would either be granted or denied by the node which currently owned the reservation. If another node was given ownership of the PR, the physical disk resource would fail over to that node and that node would begin managing access to the LUN. For more information about storage management and Persistent Reservations, check out these webcasts: TechNet Webcast: Failover Clustering and Quorum in Windows Server 2008 Enterprise Storage & Microsoft Webcast: Reducing IT Overhead with Windows Server 2008 Storage Features .
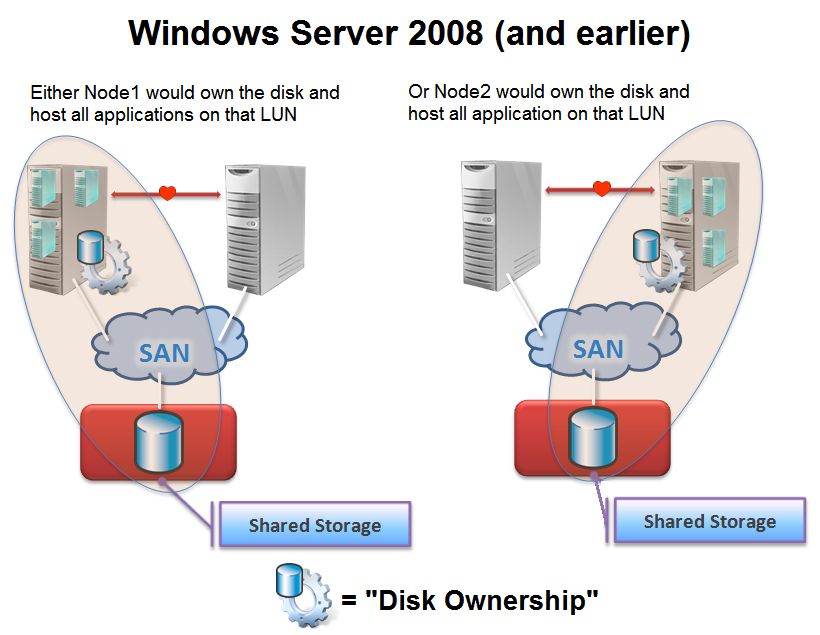
Since only one node could own the LUN at any time, this meant that the LUN became the smallest unit of failover. If any application running on the LUN needed to move to another node, it meant that all applications on that LUN would also be failed over (and have some downtime during that failover). This often meant that customers would want to run a single application in each LUN so that only one application would become unavailable during a failover. However, this added a lot of complexity to storage management, and we saw clusters with hundreds of resources needing hundreds of LUNs which was challenging to deploy and manage. It also meant that the required ‘Validate a Configuration…’ test took a long time as every LUN is tested against every node, so the duration scaled-up exponentially as more LUNs were added. So let’s take a look at how Cluster Shared Volumes solves these problems when you are clustering Virtual Machines…
Disk Ownership in R2 with CSV
Clustered Shared Volumes allows nodes to share access to storage, which means that the applications on that piece of storage can run on any node, or on different nodes, at any time. CSV breaks the dependency between application resources (the VMs) and disk resources (for CSV disks) so that in a CSV environment it does not matter where the disk is mounted because it will appear local to all nodes in the cluster. CSV manages storage access differently than regular clustered disks.
CSV gives you the ability to store your VHDs on a single LUN and run the VMs anywhere in the cluster (pass-through disks are not supported when using CSV). This will make your cluster quicker to configure and easier to manage. Additionally, CSV enables Live Migration which allows you to move a running VM from one node to another node with zero downtime. Since disk ownership no longer needs to change when a VM moves to another node, this makes the process quicker and safer, allowing clients to remain connected while the virtual machine is moved to another node in the cluster. Live migration using CSV will be explored in detail in another blog post.
But what about failures? Do not worry! CSV is resilient to failures including the loss of the Coordinator Node, the node hosting the VM, the loss of a network path and the loss of a connection to the storage. The cluster will stay up and running with little or no downtime. CSV failure resiliency will also be addressed in a future blog post.
CSV sounds great…but how much is this going to cost me?
NOTHING! That’s right – Cluster Shared Volumes comes as a standard feature with Failover Clustering in the Windows Server 2008 R2 Enterprise & Datacenter Editions and in the Microsoft Hyper-V Server R2 Edition.
While CSV could be compared to a Clustered File System (CFS), it is different in that it does not use any proprietary technology – it uses standard NTFS, so there is nothing special you need to purchase or support – it just works! You can continue to use your regular clustering storage devices – Fibre Channel, iSCSI or Serial Attached SCSI – so long as they receive a logo for R2 and the complete solution passes the “Validate a Configuration…” tests.
However, it is important to remember that in its initial release, CSV will only support highly-available Hyper-V Virtual Machines in the host partition. Of course, you can still run any service or application within that virtual machine, so long as it is supported running in a virtualized environment (KB: Supported Virtualization Environments ).
Please try out the Beta version of Windows Server 2008 R2 Failover clustering with Cluster Shared Volumes (CSV) and live migration, available here: http://www.microsoft.com/windowsserver2008/en/us/R2-Beta.aspx . For information about configuring and deploying CSV, check out this guide . Please report any bugs through the built-in ‘Send Feedback’ tool or the Microsoft Connect site, or send us your comments by clicking the ‘Email’ link in the upper-left corner of this site.
Thanks,
Symon Perriman
Program Manager
Clustering & High-Availability