- Home
- Windows Server
- Virtualization
- Using data deduplication with Hyper-V Replica for storage savings
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Protection of data has always been a priority for customers, and disaster recovery allows the protection of data with better restore times and lower data loss at the time of failover. However, as with all protection strategies, additional storage is a cost that needs to be incurred. With storage usage growing exponentially, a strategy is needed to help enterprises control their spend on storage hardware. This is where data deduplication comes in. Deduplication itself has been around for years, but in this blog post we will talk about how users of Hyper-V Replica (HVR) can benefit from it. This blog post has been written collaboratively with the Windows Server Data Deduplication team.
Deduplication considerations
To begin with, it is important to acknowledge the workloads that are suitable for deduplication using Windows Server 2012 R2. There is an excellent TechNet article that covers this aspect and would be applicable in the case of Hyper-V Replica as well. It is important to remember that deduplication of running virtual machines is only officially supported starting with Windows Server 2012 R2 for Virtual Desktop Infrastructure (VDI) workloads with VHDs running on a remote file server. Generic VM (non-VDI) workloads may run on a deduplication enabled volume but the performance is not guaranteed. Windows Server 2012 deduplication is only supported for cold data (files not open).
Why use deduplication with Hyper-V Replica?
One of the most common deployment scenarios of VDI involves a golden image that is read-only. VDI virtual machines are built using diff-disks that have this golden image as the parent. The setup would look roughly like this:
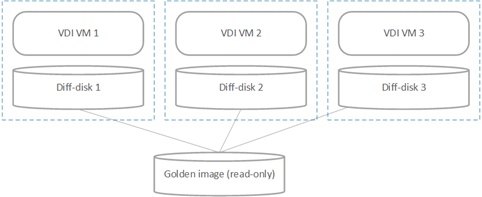
This deployment saves a significant amount of storage space. However, when Hyper-V Replica is used to replicate these VMs, each diff-disk chain is treated as a single unit and is replicated. So on the replica site there will be 3 copies of the golden image as a part of the replication.

Data deduplication becomes a great way to reclaim that space used.
Deployment options
Data deduplication is applicable at a volume level, and the volume can be made available with either SMB 3.0, CSV FS, or NTFS. The deployments (at either the Primary or Replica site) would broadly look like these:
1. SMB 3.0

2. CSVFS

3. NTFS

Ensure that the VHD files that need to be deduplicated are placed in the right volume – and this can be done using authorization entries . Using HVR in conjunction with Windows Server Data Deduplication will require some additional planning to take into consideration possible performance impacts to HVR when running on a volume enabled for deduplication.
Deduplication on the Primary site
Enabling data deduplication on the primary site volumes will not have an impact on HVR. No additional configurations or changes need to be done to use Hyper-V Replica with deduplicated data volumes.
Deduplication on the Replica site
WITHOUT ADDITIONAL RECOVERY POINTS
Enabling data deduplication on the replica site volumes will not have an impact on HVR. No additional configurations or changes need to be done to use Hyper-V Replica with deduplicated data volumes.
WITH ADDITIONAL RECOVERY POINTS
Hyper-V Replica allows the user to have additional recovery points for replicated virtual machines that allows the user to go back in time during a failover. Creating the recovery points involves reading the existing data from the VHD before the log files are applied. When the Replica VM is stored on a deduplication-enabled volume, reading the VHD is slower and this impacts the time taken by the overall process. The apply time on a deduplication-enabled VHD can be between 5X and 7X more than without deduplication. When the time taken to apply the log exceeds the replication frequency then there will be a log file pileup on the replica server. Over a period of time this can lead to the health of the VM degrading. The other side effect is that the VM state will always be “Modifying” and in this state other Hyper-V operations and backup will not be possible.
There are two mitigation steps suggested:
- Defragment the deduplication-enabled volume on a regular basis. This should be done at least once every 3 days, and preferably once a day.
- Increase the frequency of deduplication optimization . For instance, set the deduplication policy to optimize data older than 1 day instead of the default 3 days. Increasing the deduplication frequency will allow the deduplication service on the recovery server to keep up better with the changes made by HVR. This can be configured via the deduplication settings in Server Manager –>File and Storage Services –> Volume –> Configure Data Deduplication, or via PowerShell:
Set-DedupVolume <volume> -MinimumFileAgeDays 1
Other resources:
http://blogs.technet.com/b/filecab/archive/2013/07/31/extending-data-deduplication-to-new-workl...
http://blogs.technet.com/b/filecab/archive/2013/07/31/deploying-data-deduplication-for-vdi-stor...
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.