- Home
- SQL Server
- SQL Server Support Blog
- How It Works: Gotcha: *VARCHAR(MAX) caused my queries to be slower
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
The scenario:
- Table has a NTEXT column that the customer wanted converted to NVARCHAR(MAX)
- Data has both small and large storage for different rows
- Issued ALTER TABLE … ADD COLUMN …NVarCharColumn… NVARCHAR(MAX)
- Issued update MyTable set NVarCharColumn = <<NTEXT DATA>>
- Issued ALTER TABLE … DROP COLUMN .. <<NTEXT>>
Sounds harmless enough on the surface and in many cases it is. However, the issue I worked on last week was a table with 98 partitions and 1.2 billion rows (~7TB of data) that has a couple of gotcha’s you may want to avoid.
Behavior #1 – Longer Query Times For Any Data Access – Huh? Well maybe!
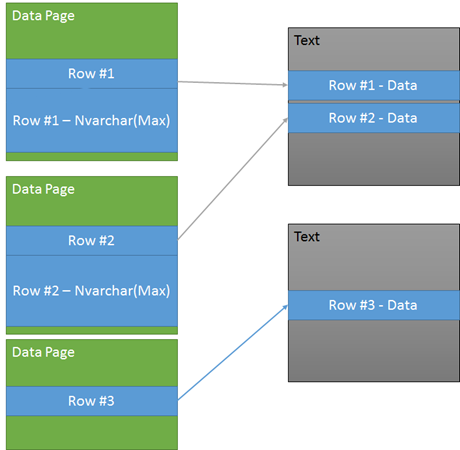
Start with a simple table containing 3 columns (A = int, B = guid and C = NTEXT). As designed the data page has a TEXT POINTER to the NTEXT data. The TEXT POINTER takes up ~16 bytes in the row to point to the proper text chain.

When you run a select A, B from tblTest a single page is read because column C is an off-page action and we are not selecting the data for column C.
Now lets convert this example to NVARCHAR(MAX) and allow the table to inline the NVARCHAR(MAX) column.

From the diagram you can see that the TEXT pages are no longer present for rows 1 and 2, as the data was moved inline. This happens when the data is small enough to be stored inline with the row data instead of off page ( as shown with Row #3 addition to the example. )
Now if you run the same select A, B from tblTest you encounter 2 data page, I/Os for row 1 and 2 because the data values are not as compact when the NVARCHAR(MAX) data is stored inline. This additional overhead can lead to slower query performance, reduced page life expectancy and increased I/O even when the column(s) you are selecting do not include the NVARCHAR(MAX) data.
The following blog is a great reference about this very subject: “ http://stackoverflow.com/questions/1701808/should-i-use-an-inline-varcharmax-column-or-store-i... ” The blog specifically outlines the sp_tableobject ‘large value types out of row’ usage and the use of column %%physloc%% to determine your *VARCHAR(MAX) storage properties.
Behavior #2 – Text Data Not Cleaned Up?
Specifically I want to focus on the original NTEXT column and the associated DROP COLUMN. In the scenario the NTEXT column was dropped using ALTER TABLE … DROP COLUMN. At first you may think this cleans up the TEXT data but that is not the case. The cleanup happens later, when row is modified.
From SQL Server Books Online: http://msdn.microsoft.com/en-us/library/ms190273.aspx
|
Dropping a column does not reclaim the disk space of the column. You may have to reclaim the disk space of a dropped column when the row size of a table is near, or has exceeded, its limit. Reclaim space by creating a clustered index on the table or rebuilding an existing clustered index by using ALTER INDEX . |
Even after the ALTER TABLE … DROP COLUMN <<NTEXT>> the PHYSICAL layout of the data looks like the following. Double the storage in the database but the meta data has been updated so to the outside, query world, the column no longer exists.
Now the customer issues an index rebuild and it is taking a long time for the 1.2 billion rows and SQL Server is not providing detailed progress information, just that the index creation is in-progress.
The early phase of the index creation is cleaning up the rows, in preparation for the index build. In this scenario the SQL Server is walking over each data row, following and de-allocating the specific row’s text chain. Remember the text pages could be shared so each chain has to be cleaned up, one at a time. This cleanup is a serial ( not parallel ) operation! For the customer this means running 1.2 billion TEXT chains and doing the allocation cleanup on a single thread.
What would have been better is to update the NTEXT column to NULL before issuing the DROP COLUMN statement. The update could have run in parallel to remove the text allocations. Then when the index creation was issued the only cleanup involved is the single (NULL BIT) in the row data.
Note: With any operation this large it is recommended you do it in row batches so if a failure is encountered it only impacts a limited set of the data.
Specifically, if you issue the ALTER TABLE from SQL Server Management Studio, query window on a remote client and this remote client was rebooted; the query is canceled (ROLLED BACK). After running for 24+ hours this also is a lengthy rollback lesson to learn.
DBCC CLEANTABLE - http://msdn.microsoft.com/en-us/library/ms174418.aspx
The
cleantable
command is another way to help cleanup dropped, variable length columns and allows you to indicate a batch size as well.
However, this command is run in serial (
not parallel
) as well and just like the create index a stability lock on the object is acquired and held during the processing. Again, it may be better to issue a update to NULL and then
cleantable.
Bob Dorr - Principal SQL Server Escalation Engineer
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.