- Home
- SQL Server
- SQL Server Blog
- A practical example on missing a filtered index
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Hello all,
Last week I did a brief presentation on SQLPort about hinting the database engine. What’s related here is that during the presentation, when I was discussing index hints, an attendee asked me about the usefulness of Filtered Indexes in certain scenarios, and how the database engine would behave differently in SQL Server 2008R2 and SQL Server 2012. I quickly pulled out my filtered indexes demo, but still he was adamant that something had to be different between engine versions.
Later, he was kind enough to send me a piece of code that he stated would generate different query plans in SS2008R2 and SS2012, respectively, namely where SS2008R2 would choose a non-filtered non-clustered index to resolve a simple query, whereas SS2012 would choose the filtered non-clustered index.
To test that, I used SQL Server 2008R2 Build 2769 and SQL Server 2012 Build 2100. I couldn’t find any differences between the generated plans on different engine versions for the given parameters.
Here is a close adaptation of what I was sent. All screenshots are from 2008R2 only.
Create a new database:
SET NOCOUNT ONGO
CREATE DATABASE FiltIXTest
GO
USE FiltIXTest
GO
Then create a table and populate:
CREATE TABLE t1 (c1 int identity(1,1) PRIMARY KEY, c2 char(50), c3 varchar(50))
GO
DECLARE @r float, @u float
SET @r = 97 + CAST(RAND() * 20 as int)
SET @u = 97 + CAST(RAND() * 10 as int)
INSERT INTO t1 VALUES (CHAR(@r), CHAR(@u))
GO 20000
INSERT INTO t1 VALUES (NULL, NULL)
GO 50000
Then create filtered and unfiltered indexes:
CREATE INDEX IX_c2 ON t1(c2)
GO
CREATE INDEX IX_c2Filtered ON t1 (c2)
WHERE c2 IS NOT NULL
GO
And the queries to test on, with the original comments:
- The 1st query was expected to use IX_c2Filtered index
- The 2nd query is like the 1st, but with an index hint on the filtered index.
SET STATISTICS IO, PROFILE, TIME ON
GO
DBCC FREEPROCCACHE
GO
DBCC DROPCLEANBUFFERS
GO
-- This should use the filtered index, but it only worked in SQL Server 2012
SELECT c2 FROM t1
WHERE c2 IS NOT NULL
GO
DBCC FREEPROCCACHE
GO
DBCC DROPCLEANBUFFERS
GO
-- When compared in the execution plan, a large percent difference is noticeable.
SELECT c2 FROM t1 WITH(INDEX (IX_C2Filtered))
WHERE c2 IS NOT NULL
GO
So here are the plans for this:

Let’s not get carried away by the apparent query cost percentage. This is just an approximation done by SSMS, not the database engine itself.
That said, the I/O statistics show 157 logical reads for the 1st query, 154 for the 2nd. The time statistics show a total execution time of 13ms for the 1st query, and 23ms for the 2nd. Not that different in terms of I/O. What comes across right away is the type of operation. An Index Seek on IX_c2 and the expected Index Scan on IX_c3Filtered.
So let’s look at the statistics related to these indexes. I highlighted a few differences that will help explain why the query optimizer might have chosen to leverage the unfiltered vs. the filtered index:

What we see here is that there is almost no difference in the number of steps in the histograms. That is obviously because the index WHERE clause is not very narrow. Then we see the average key length, 66% larger in the filtered index, because NULLs do not exist here to average it down. Finally a very small difference in the density vector for the key column, with 0.047 for IX_c2 and 0.05 for IX_c2Filtered. Also bear in mind that the filtered index covers almost 40% of all data that is 20.000 rows out of 70.000. The filtered indexes guidelines only refer to the term “subset” when providing insight on filtered index design. In that sense, 40% is hardly a “subset”.
What can also be observed is that the indexes are string based, or tried tree based. Overall we might not have the best candidate for a filtered index. This condition is not narrow enough to leverage the full power of what filtered indexes brought us back in 2008, and is more costly to use it in this scenario.
I ran the example again, but changing one of the strings to an integer, to get a numeric based index.
Create a new database:
SET NOCOUNT ON
GO
CREATE DATABASE FiltIXTest3
GO
USE FiltIXTest3
GO
Then create a table and populate it:
CREATE TABLE t3 (c1 int identity(1,1) PRIMARY KEY, c2 int, c3 char(20))
GO
DECLARE @r float, @u float
SET @r = 97 + CAST(RAND() * 20 as int)
SET @u = 97 + CAST(RAND() * 10 as int)
INSERT INTO t3 VALUES (@r, REPLICATE(CHAR(@u),20))
GO 20000
INSERT INTO t3 VALUES (NULL, NULL)
GO 50000
The indexes again:
CREATE INDEX IX_c2 ON t3(c2)
GO
CREATE INDEX IX_c2Filtered ON t3 (c2)
WHERE c2 IS NOT NULL
GO
And the queries to test on:
- On the 1st query the filtered index should be used.
- On the 2nd query, I’m forcing the unfiltered non-clustered index to se the differences.
SET STATISTICS IO, PROFILE, TIME ON
GO
DBCC FREEPROCCACHE
GO
DBCC DROPCLEANBUFFERS
GO
SELECT c2 FROM t3
WHERE c2 IS NOT NULL
GO
DBCC FREEPROCCACHE
GO
DBCC DROPCLEANBUFFERS
GO
SELECT c2 FROM t3 WITH(INDEX (IX_C2))
WHERE c2 IS NOT NULL
GO
Let’s check the execution plans:

The I/O statistics show 37 logical reads for the 1st query, 39 for the 2nd. The time statistics show a total execution time of 14ms for the 1st query, and 15ms for the 2nd. Not much difference both I/O and time wise. As expected, an Index Scan on IX_c2Filtered and an Index Seek on IX_c2.
Let’s look at the statistics related to these indexes. Again, I highlighted a few differences that will help explain why the query optimizer might have chosen to leverage the filtered vs. the unfiltered index.

Again we see almost no difference in the number of steps in the histograms. Then we see the average key length, only 33% larger in the filtered index. The same small difference in the density vector for the key column, with 0.047 for IX_c2 and 0.05 for IX_c2Filtered.
Much smaller differences between both indexes than in the previous example, this time the Query Optimizer leveraged after weighing all factors.
Of course, if we introduced a more narrow index, such as the following:
CREATE INDEX IX_c2Filtered_2 ON t4 (c2)
WHERE c2 < 100
GO
and queried on:
DBCC FREEPROCCACHE
GO
DBCC DROPCLEANBUFFERS
GO
SELECT c2 FROM t4
WHERE c2 < 99
GO
We would have little doubt the new filtered index would be chosen:
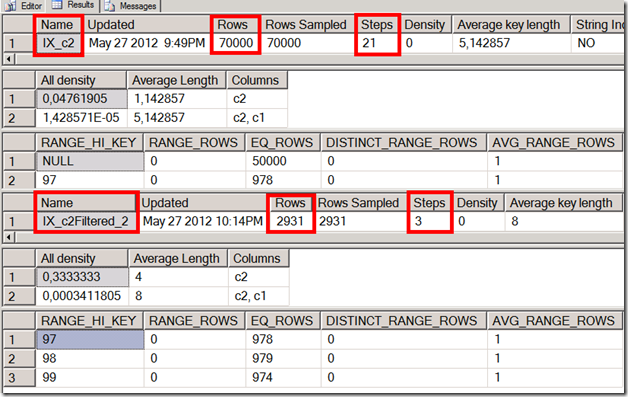
Having filtered indexes in place does not mean a query will always use them. You can get more information on how SQL Server uses statistics
here
.
Statistic information might show, as was the case earlier, that seeking the unfiltered non-clustered index would be effective enough, if the filtered index is not that narrow.
Bottom line, know your data, your index design, its distribution statistics, and test, test, test.
Until next time!
Disclaimer: I hope that the information on these pages is valuable to you. Your use of the information contained in these pages, however, is at your sole risk. All information on these pages is provided "as -is", without any warranty, whether express or implied, of its accuracy, completeness, fitness for a particular purpose, title or non-infringement, and none of the third-party products or information mentioned in the work are authored, recommended, supported or guaranteed by Ezequiel. Further, Ezequiel shall not be liable for any damages you may sustain by using this information, whether direct, indirect, special, incidental or consequential, even if it has been advised of the possibility of such damages.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.