- Home
- Exchange
- Exchange Team Blog
- Speech recognition of names by Exchange 2007 unified messaging
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Introduction
Exchange Server 2007 Unified Messaging (UM) supports automatic speech recognition (in English, only). UM-enabled users who call into UM can speak to it for command and control in Outlook Voice Access (e.g. "Next message", "I'll be 20 minutes late"). They can also use speech recognition for directory searches. Callers who are connected to a speech-enabled UM automated attendant can benefit greatly from a speech-enabled directory. It is much easier for a caller to say the name of the person they want to contact than to spell the name, or enter the extension number, with the telephone keypad,
UM builds speech grammars to constrain speech recognition's job. One or more grammars are active when UM is listening for speech input. Some of these grammars are used for command and control. These are installed with the product and do not change unless they are upgraded in a Service Pack, or later release. However, the grammars that constrain speech recognition for the directory cannot be created until UM has been installed at the customer site.
Speech access to Active Directory is a very powerful feature of UM. However, speech recognition is not infallible, names may have unexpected pronunciations, and callers will not know how the name is entered into the directory[1]. While UM may do a reasonable job of name recognition "out of the box", it is likely that some fine-tuning will be needed to get the best results.
This document describes the way in which UM builds speech grammars, and explains how customer-specific adjustments can be made to improve the overall success of speech access to the directory.
Speech Grammars created from Active Directory by UM
Types of Grammar
UM may create several speech grammars from Active Directory. Each is tailored to a particular scope (GAL, Dial Plan, or Address List). By default, callers to a Dial Plan's pilot number, or to an associated Automated Attendant, can contact anyone in that Dial Plan. By default, UM users who log into their mailbox have access to the Global Address List[2]. Therefore, a UM server will generally create a grammar for the GAL, and another for each Dial Plan to which it belongs. Additional grammars are created as required. For example, an Automated Attendant may have a contact scope defined by a particular address list.
UM users logged into Outlook Voice Access are also able to send voice messages to distribution lists. A grammar containing DL names is created to support this feature.
Speech grammars created from the directory contain a set of definitions, each of which comprises a name (usually the name of a user) and a unique identifier (because two or more users may have the same name). When a caller speaks a name, UM passes their speech into the recognition engine, which searches the grammar(s) for names that match. More than one user may share the same name, and some names that are spelled differently sound identical, or very similar. Therefore, several possible matches may be found. If this happens, UM then tries to help the caller to find the actual user whom they want to contact.
Generation Schedule
Each UM Server will generate the speech grammars that it needs. This activity requires queries to Active Directory, and computation on the results. Its consumption of resources makes it desirable to run the activity at off-peak hours. The timing is controlled by a property on the UMServer object. The property is called GrammarGenerationSchedule. It describes a seven-day, recurring timetable, referred to local time (i.e. system time on the UM server). The times of grammar generation are determined by the following rule:
- Grammar generation will run once in each active period on the schedule, at the start of the period (except when prohibited by rule 4).
- Existing grammars will be replaced.
- Once started, grammar generation will run to completion, through all the grammars required by the UM Server.
- Grammar generation will not start within an hour of a previous generation.
By default, the schedule contains a single active period, starting at 2:00 AM. Automatic grammar generation will therefore run once per day (unless the schedule is changed to specify otherwise).
Where there are multiple UM Servers in a Dial Plan, it may be advantageous to adjust the grammar generation times to be different on the different servers. This spreads out the query load on the Active Directory.
Scheduled grammar generation is recorded by Windows informational events from UM in the application event log. Event number 1131 records the start of a scheduled grammar generation. Event number 1132 records the end of a scheduled grammar generation.
On-Demand Generation
Speech grammars are generated if they are referenced by configuration but are not found when the UM service starts. This means that grammars will be generated automatically after the UM role is first installed on a server.
Another way to generate grammars is to use the GALGRAMMARGENERATOR.EXE tool (in %ExchangeRoot%\bin). This is provided for help with troubleshooting: it should not be needed in normal operation.
What UM Extracts from Active Directory into its Speech Grammars
UM is selective about the directory objects that it will examine when creating a speech grammar. The types of objects selected depends on the scope of the grammar.
For the GAL grammar, UM will extract the names and identities of:
- Mail-enabled users
- Mail-enabled contacts
For Dial Plan grammars, UM will extract the names and identities of:
- UM-enabled users in the specified Dial Plan
For the distribution list grammar (used only by Outlook Voice Access), UM will extract the names and identities of:
- Distribution lists that are visible in address lists
Conversion and Filtering of Names from Active Directory into Speech Grammars
Objects in Active Directory have display names. If an administrator adds a user to the directory with the Active Directory Users and Computers administrative tool, the display name of the user is usually formed by concatenating the user's first name, middle initials (if any) and last name.
However, the display name thus created - though suitable for users who can see it in the address book - may not be in a form that callers will actually say (see footnote 1). There are other reasons why the display name may not be a good identifier in the speech grammar. For example:
- It may be preceded by a title (e.g. Mr., Ms., Dr.)
- It may be followed by a suffix (e.g. Jr., III)
- It may be of the form Last name, First name.
- It may be followed by organization-specific codes (e.g. department, location)
All these effects combine to reduce the probability that a given user's name will be inserted into the speech grammar in a form that will be spoken by callers. Organizations often have policies about the means of creation and layout of user's display names in Active Directory. They should not be forced to change these working practices because of UM. Therefore, UM offers administrators some control over the transformation of display names into names that are inserted into the speech grammar.
Figure 1 shows an example of the processes that take place during grammar generation. For clarity, only a single user is shown.
Processing a users name(s) for a speech grammar:
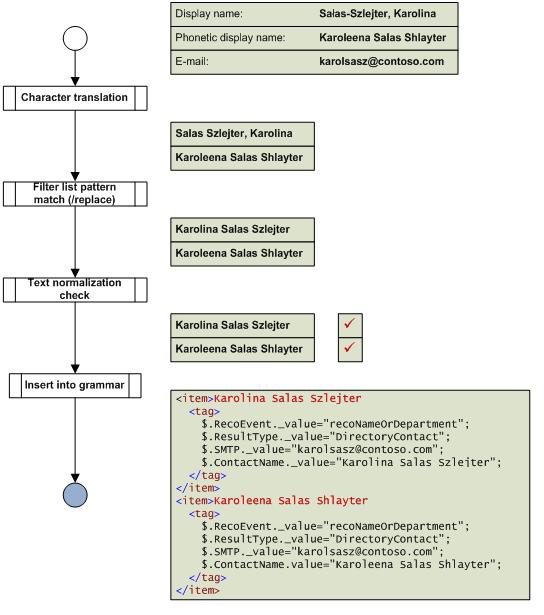
The user's display name is "Salas-Szlejter, Karolina". This name has four features that make it unsuitable for insertion into the speech grammar in its original form.
- The last name precedes the first name. Callers will expect (and it is much more natural) to speak the first name, and then the last name.
- The correct pronunciation of Szlejter sounds like Shlayter. People who know Karolina will undoubtedly get the pronunciation right, although the speech recognition and text-to-speech systems may not have this knowledge. People who do not know Karolina may well get the pronunciation wrong, in which case their naive guesses may actually approximate those of the speech engine.
- The first part of the surname (Salas) contains a character (small letter 'L' with stroke) that may cause problems for speech recognition or text-to-speech systems that are unfamiliar with the character..
- The dash between Salas and Szlejter, although not significant to the way that the caller pronounces the name, may be interpreted literally by the speech engine. In fact, it may allow for multiple forms, such as "dash" and "hyphen", as well as for a silent form.
Point 4 may not seem as important as the other three - after all, if the "correct" (silent) pronunciation of the dash is accounted for, why worry? However, UM deliberately rejects names that are considered to have multiple equivalent forms, for reasons of efficiency and overall accuracy[3].
There are three stages in the preprocessing of a directory object for the speech grammar (once the directory query has returned the object's display name, etc.). These are shown in Figure 1.
Character Translation
First, character translation takes place. In Exchange Server 2007 UM, only English language speech recognition is supported. One function of character translation is to render accented characters, digraphs and other special characters into forms more suitable for an English speech engine. For example, 'á' will become 'a' , the 'l' in the example above will become a plain 'l', and 'ß' will become 'ss'. The other function is to remove characters commonly found in people's names that do not contribute to the pronunciation. It is at this stage that '-' will become ' ' (space).
Pattern Filtering
Next, pattern filtering takes place. The name (after character replacement) is compared to a series of patterns, described by regular expressions.[4] Each pattern has an associated set of replacement patterns, that may be used to transform the name in various ways. Multiple replacement patterns are possible: a name from the directory may therefore give rise to more than one name in the speech grammar. Once a match (and possible associated transformation of the name) has been made, the search stops: no more patterns are examined for that name. If no match is found, the name is passed through this stage unchanged.
The pattern filtering is controlled by the rules in a file called SpeechGrammarFilterList.xml, a copy of which is installed on every UM server.
Here is an example of a filter rule:
<Pattern>
<!- Firstname (Nickname) Lastname ->
<Input>^(\w+)\s+\((\w+)\)\s+(\w+)</Input>
<!- ==> Nickname Lastname ->
<Output>$2 $3</Output>
<!- ==> Firstname Lastname ->
<Output>$1 $3</Output>
</Pattern>
The <Input> element attempts (via a regular expression) to match names such as "Timothy (Tim) Sneath" that consist of a first name, a middle name in parenthesis, and a last name. Middle names that are bracketed this way conventionally represent nicknames. As such, they represent a likely way that callers will name the user.
There are two <Output> elements for this rule. The first emits the middle name (thought to be a nickname) and last name, e.g. "Tim Sneath". The second emits the first name and last name, for those people who either do not know the nickname, or prefer to use the more formal first name, e.g. "Timothy Sneath".
For this user example, this means that UM will accommodate callers who say either "Tim Sneath" or "Timothy Sneath". This addresses the problem described in footnote 1.
No special configuration is required to get this particular behavior. This (and a number of other "generic" patterns) ship with in UM's speech grammar filter list.
Text Normalization Check
The final stage of directory name processing consists of a check with the speech engine that there is only one way to say the name (after any transformations in the previous two stages). As explained in footnote 3, this is a performance optimization.
Insertion into Speech Grammar
If the name passes the text normalization check and is not empty, it is inserted into the speech grammar. If not, an entry recording the reason for its omission is logged to a file. The name and location of the log file are recorded in UM event 1139 (informational). The name and location of the grammar file are recorded in UM event 1140 (informational). Grammar files have a .grxml extension, and are compliant with the Speech Recognition Grammar Specification[5], or SRGS.
Configuring Speech Grammar Generation by UM
Most probably, some callers will report that their attempt to contact a user failed because the UM system did not recognize the name that they said. There are two basic reasons why this may happen:
- The user's details are not in the speech grammar.
- The user's details are in the speech grammar, but what the caller said was not recognized correctly.
If the user's details are not in the speech grammar[6], the reason is either that they were not mail-enabled, or that the name failed the text normalization check. Further details on the latter type of failure can be found in the grammar generation log file.
As the preceding descriptions should have made clear, there are many reasons why the user may not be recognized, even if the caller says their name. These can be subdivided into:
- Recognition errors. The caller's speech was matched against the wrong name(s), or none at all.
- Name errors. The caller spoke a form of the user's name different from that in the grammar.
There are many reasons why type (1) errors may occur. The caller may be speaking over a noisy connection. The caller may speak indistinctly, or very softly. There is little or nothing that the UM administrator can do about this.
Type (2) errors can be reduced if the administrator is able to anticipate the kinds of mismatch that occur between the users' display names, as written, and their names as callers might speak them.
The speech grammar filter list (see Pattern Filtering, above) is intended to be applied to names in bulk. However, problems with names are often related to individual entries. Figure 1 illustrates a case where the user's display name (Salas-Szlejter, Karolina) is in the reverse order to what a caller might say. This is handled by the speech grammar filter list. However, the resulting name (Karolina Salas Szlejter) may be a challenge for callers who have only the written or printed name to guide them.
The solution to this and similar problems is to define a second display name for the user. This is called the phonetic display name. In the Active Directory, as extended by Exchange Server 2007 organization preparation, it is stored as a string attribute called msDS-PhoneticDisplayName.
UM uses the phonetic display name (if present) in two ways.
- If the user has not recorded their nam e (for example, if they are mail-enabled but not UM-enabled), UM will play the phonetic display name (in preference to the display name) when it uses text-to-speech conversion to speak the name.
- UM will process the phonetic display name, as well as the display name, when creating a names speech grammar.
The phonetic display name for the user in Figure 1 has been entered by the administrator as Karoleena Salas Shlayter. Although this is not the correct spelling, it it much more likely to be matched by the speech engine to a correct pronunciation of the name. The processed display name, on the other hand, can be used to represent a naive pronunciation of the name.
To set the phonetic display name, administrators can use a directory tool such as ADSIEdit. However, it is also possible (and it may be easier) to use the Set-User cmdlet that is installed with the Exchange Management Shell, for example:
Set-User -Identity karolsasz@contoso.com -PhoneticDisplayName "Karoleena Salas Shlayter"
Summary
Exchange 2007 Unified Messaging provides speech recognition services to help callers contact users just by speaking their name. However, user names as stored in Active Directory are often better suited to visual display than to speech recognition. They may have the last name first, or be spelled in such a way that the pronunciation is hard to guess by software, or by callers.
UM uses a grammar generation process that can rearrange common names in a way that makes them more likely to be recognized from speech. For individual cases, UM allows the administrator to provide a per-user phonetic display name, which can be used to provide the speech engine with a textual version of the name that more closely matches what callers are likely to say.
[1] Consider a user whose name appears as "Timothy (Tim) Sneath", in the directory. While this is visible to those who have access to the Exchange Address Book, or some other view of the directory, it is invisible to UM callers, who may say "Timothy Sneath" or "Tim Sneath" when asked who they want to contact.
[2] Note that dialing rules and other properties may limit the user's ability to contact a person in the directory.
[3] Consider the display name "Room 12/305". Such names could be present in the directory in large numbers, representing mail-enabled resources (conference rooms). The speech engine would automatically generate many equivalent forms of such a name (of which "Room twelve slash three hundred and five" and "Room twelve three oh five" are only two). Such names would rapidly bloat the dynamic grammar, and tend to reduce the speed and accuracy of recognition.
[4] More specifically, the .NET flavor of regular expressions is used. See http://msdn.microsoft.com/library/default.asp?url=/library/en-us/cpguide/html/cpcondetailsofregulare... for details.
[5] See http://www.w3.org/TR/speech-grammar/
[6] The quickest way to tell whether a user is in the grammar or not is to search the file for their e-mail alias, e.g. findstr /i karolsasz@contoso.com gal.grxml
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.