- Home
- Exchange
- Exchange Team Blog
- Patching the Multi-Role Server DAG
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
One of the things about Exchange 2010 that many of my customers find very attractive (and I have to agree with them) is the idea of the multi-role or “all-in-one” DAG server. This means having all three of the core Exchange 2010 roles installed on all of the servers in the DAG – Mailbox, Hub Transport and Client Access. There are a lot of reasons why this is an attractive solution, but here are a few of the main ones:
- All servers in the Exchange environment (discounting Unified Messaging and Edge) are exactly the same – same hardware, same configuration, etc. This simplifies ordering the hardware, maintenance and management of the servers.
- In many cases you end up with less Exchange servers in the environment. This is interesting because usually the operational expenditure is higher than the capital expenditure, meaning that it costs more to run a server than it did to purchase it in the first place.
- Less servers means that you also have less of some other things – a sort of “trickle down” effect. For instance, you might have a lower number of network switch ports needed, and for large customers this could be significant. Or maybe you need less physical space for these servers, and for some customers, space is a significant issue.
- The idea of “all roles on one server” allows you to take full advantage of the new hardware capabilities out there today. As part of the design, you want to ensure you utilize as much of the hardware as possible to drive down the cost/mailbox; the latest hardware is quite fast from a megacycle perspective, which means you are either increasing the scale on the server in terms of the number of mailboxes, virtualizing or deploying multiple roles. For the multi-role server, Microsoft supports up to 24-cores – that is a 4-socket, 6-cores per socket server. Granted, this is only useful for larger customers, but for those larger customers it can be quite important!
But, when talking about these multi-role solutions, I always make sure to let my customers know that this is a starting point, even though this is the preferred deployment model for Exchange 2010. Exchange 2007 didn’t support CAS and HT on clustered servers, and we took a lot of customer feedback to help us decide that we needed to support that in Exchange 2010. We believe this is the best deployment model for Exchange. If you feel that this will not meet your requirements, well, having separate CAS/HT servers (or separate CAS and separate HT servers) is fully supported and is still a valid solution model.
In fact, there are a couple of things that you need to carefully consider before deciding that the multi-role server is right for you. First is the idea that by putting your CAS role on the DAG member servers, you are forcing yourself to require a hardware load balancer (or third party software load balancer). The DAG still leverages Windows Failover Clustering as a container that defines the boundaries of the DAG and to help the DAG determine whether quorum can be met (amongst other things). When you combine that fact with the idea that you cannot have Windows Load Balancing Services loaded on a server that also has Windows Failover Clustering loaded, you are forced to find another solution for load balancing. For smaller customers, or for branch office scenarios, this might be a deal-breaker. There are some less expensive hardware load-balancing solutions out there, but for some customers, even those might be too expensive, which means that this multi-role server idea won’t work.
Another thing to consider as you determine the architecture you want to utilize for your Exchange 2010 environment is how you will patch your highly available servers. You don’t deploy a DAG unless you really need mailbox resiliency within the datacenter and/or between physical locations – it is a very expensive way to deploy Exchange 2010 if your requirements don’t drive you to need mailbox resiliency! So, if you are spending that money, you need to make sure you understand how to patch these servers and provide the highest level of availability possible.
As you think about these multi-role solutions, also remember the fact that all of the Client Access role servers will be identified as part of the CAS array in a given Active Directory site (this is automatic). When you configure your hardware load balancers, you will need to add all of these Client Access servers into the load-balanced array to allow them to actually be utilized for client access. But, if you’ve done that, how do you patch your servers? If you patch one of the servers (for ease of writing, let’s assume RTM to RU1) and add it back into the array, you now have the possibility a Client Access server at RTM (one of the un-patched servers) fronting a mailbox on RU1 (the newly patched server)! Not good – we all know that you patch these servers in alphabetical order – CAS, HT, MBX – and that means you aren’t supposed to have the mailbox at a newer build than the Client Access server!
So, what do you do about that? We’ll look at some scenarios in the rest of this article, and talk at a high level about the process you’ll take to ensure that you don’t get into a situation where your mailbox is at a newer build than the CAS in front of it.
All of the scenarios below have the patching impact that you will have to manipulate your load-balanced array every time you patch your servers. This possibly means coordinating with another team and putting some management load on them. Of course, any time you patch a CAS array, you’ll probably need to interface with the load-balancer team anyway – you need to “drain stop” each individual CAS server as you patch it anyway to keep the client disconnects and reconnects as low as possible. So, really, this might add a little management overhead to the load-balancer team, but it is possible that it isn’t a significantly high amount of additional work.
The only way you can balance this “additional work” for the load-balancer owners is the fact that HA costs money. You have to remember that. The higher you want your availability to be, the more it costs. Whether it is you or one of your customers, this core tenet of HA must be kept in mind. The other option is to just say that your maintenance window is a time when taking email services completely down is acceptable. But, then again, if you’re spending all this money on HA, is that really an option?
Patching Scenario – Small Office / Branch Office
This is the simplest DAG architecture out there. We’re talking about a single DAG in a single location with only 2 or 3 servers. This is for HA only – no site resilience. For our example here, we’ll look at a 3-member DAG – see this simple diagram:
How do we patch this DAG? Here are a few steps:
- As is always necessary when moving databases around on your DAG, ensure that your replication is healthy and all copies are up to date. For the purposes of this example, we’ll start the upgrade process with Server 3.
- Activation block Server 3 so that a failure at this time won’t activate copies of the mailbox databases on that server.
- Perform a switchover of all databases away from Server 3 to Server 1 and Server 2.
- Drain-stop all connections to the CAS on Server 3, and then remove it from the load-balanced array (note that we do not remove the server from the CAS Array) and patch it.
- Add Server 3 back into the load-balanced array, drain-stop Server 1 and Server 2 and remove them from the load-balanced array.
- Notice that for a short period, we have both upgraded and not-upgraded servers in the load-balanced array. This is not an issue, because we still have all mailboxes on the not-upgraded mailbox servers.
- Remove the activation block on Server 3, activation block Server 2, perform the switchover of all databases from Server 2 to Server 1 and Server 3, patch Server 2 and add it back into the load-balanced array.
- Remove the activation block on Server 2, activation block Server 1, perform the switchover of all databases from Server 1 to Server 2 and Server 3, patch Server 1 and add it back into the load-balanced array.
- Remove the activation block on Server 1, and redistribute your databases evenly across all three servers (Note that there will be a pretty sweet script in Exchange 2010 Service Pack 1 to do this for you!).
Impact(s) of this process:
- At that time when you have patched a single server and you have the entire load-balanced array pointing at that one server (in our example above, when Server 3 has been added into the load-balanced array and Servers 1 and 2 have been removed from the load-balanced array), you have no HA on your CAS services. This makes the assumption that at the time of patching, that one CAS server can handle the load sufficiently. Until you have patched your second server and added it into the load-balanced array, you could have a service interruption by the failure of that one server.
- Remember that this is only for the time period that you have not patched that second server and added it back into the load-balanced array.
- Also remember that under normal conditions, this process will cause less interruption of service than taking the entire system offline for the time that we need to patch the 2 or 3 servers – so in most instances you will be at a higher level of availability than you would be if you didn’t follow this procedure.
- You should also keep in mind that during this patching process, you cannot take two servers offline at the same time – a three member DAG (as shown in our example) will lose quorum when you take two members down, and all email services will be unavailable in that case.
Patching Scenario – Medium Sized Deployment
This is a slightly larger environment – a single DAG with 4 or more servers in the DAG, all located in one location. Let’s use a 6-member DAG for our example this time. Refer to this diagram for this example:
Also note that for this example, we’re going to say that we have designed this DAG to support two concurrent failures. This means that if we take two servers out of actively hosting mailboxes for patching, by having three copies of all databases, we are assured that we can continue to provide email services. It is possible to modify this solution to only take a single server out of service at a given time, and that is a perfectly acceptable solution – this is just an example presented here for discussion.
- Ensure that your replication is healthy and all copies are up to date.
- In our example we are going to patch two servers at a time, starting with Server 5 and Server 6.
- Activation block Server 5 and Server 6 so that a failure at this time won’t activate copies of the mailbox databases on those servers.
- Perform a switchover of all databases away from Server 5 and Server 6 to the other four servers in the DAG.
- Drain-stop all connections to the CAS on Server 5 and Server 6, and then remove them from the load-balanced array
- Patch Server 5 and Server 6.
- Add Server 5 and Server 6 back into the load-balanced array, drain-stop all other servers and remove them from the load-balanced array.
- Notice that for a short period, we have both upgraded and not-upgraded servers in the load-balanced array. This is not an issue, because we still have all mailboxes on the not-upgraded mailbox servers.
- Remove activation block from Server 5 and Server 6, activation block Server 3 and Server 4, perform the switchover of all databases from Server 3 and Server 4 to the other four servers, patch Server 3 and Server 4 and add them back into the load-balanced array.
- Remove activation block from Server 3 and Server 4, activation block Server 1 and Server 2, perform the switchover of all databases from Server 1 and Server 2 to the other four servers, patch Server 1 and server 2 and add them back into the load-balanced array.
- Remove activation block from Server 1 and Server 2, and redistribute your databases evenly across all three servers.
Impact(s) of this process:
- For a period of time, you will be running with a possibly lower availability stance than normal operating conditions. You only have 2 servers providing CAS services until you have patched those other servers and added them back into the load-balanced array. (If you only have 4 servers in the DAG, this might not be the case.)
- In the case where you have very high numbers of users in this physical location, it is possible that you would introduce a performance impact on CAS services, because of the reduced number of Client Access servers in service.
- Think about the situation where you have 8 or 10 servers in the DAG in this physical location, and you have only patched 2 servers. In that case, those 2 servers could probably not handle the load of all users under full production load. But, you typically won’t be patching during a “full production” time of the day – you’ll have a maintenance window that you will be working in, and users will know to have a lower expectation of availability and such. As long as you understand this and are willing to accept this risk, this is fine, but you should almost certainly make sure that you document this case and make sure that it really is acceptable!
- The other way to think about this is to make sure that the two servers you bring back into the load-balanced array have enough processing power and memory to support the entire load. This is probably the best engineering solution for a highly available Exchange 2010 environment, but it does have a cost associated with it just like everything else in HA. If I were going to recommend a solution, this is how I would recommend it – make sure you have enough processing that if you end up in a production environment on two upgraded servers, that they can handle your full production peak load.
Patching Scenario – Large Deployment
Multiple DAGs, multiple servers in each DAG, DAGs spread across multiple locations. Think about the scenario where you have two datacenters with two DAGs of 12 servers each, and users active in both datacenters. At any given time, you have 6 servers in a passive mode in each of the two datacenters. This is for big customers – a lot of my customers are very large, and I’m working with three customers right now: 120K mailboxes, 250K mailboxes and 600K mailboxes.
To help define this environment, here is a relatively simple diagram of two DAGs showing the replication data flow direction.
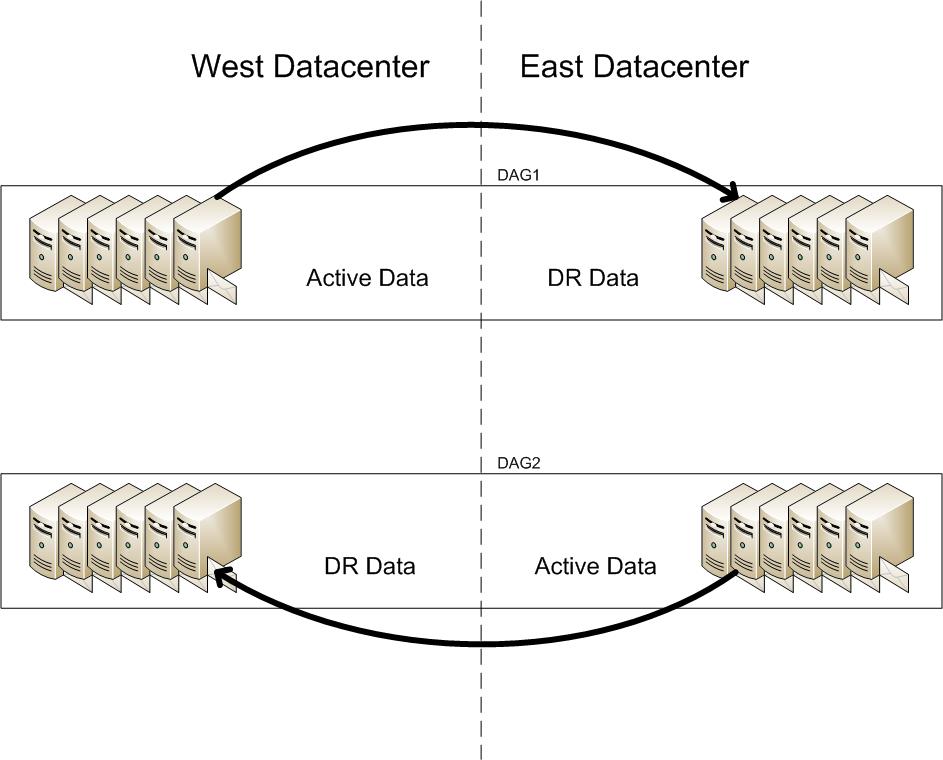
Now, how to patch this beast… This example will discuss patching the West Datacenter servers – just repeat this process for the East Datacenter after completing the West Datacenter upgrades.
- Ensure that all replication is healthy and all copies are up to date on both DAGs.
- Activation block all of the DAG2 servers in the West Datacenter to keep databases from failing over to these servers.
- Ensure no databases from DAG2 are active in the West Datacenter. If so, perform the switchovers necessary to move those databases back to the East Datacenter and ensure that all replication comes back healthy and all copies come up to date.
- In the West Datacenter only, drain-stop all of the servers in DAG2 and remove those servers from the West Datacenter load-balanced array.
- Patch all DAG2 servers in the West Datacenter.
- Add all DAG2 servers in the West Datacenter back into the load-balanced array and remove the activation block on those servers.
- Drain-stop all DAG1 servers in the West Datacenter and remove them from the West Datacenter load-balanced array.
- Work through the DAG1 servers patching them “two by two”. This means to move active mailboxes off the servers two at a time, patch those two servers, move databases off of two more servers, and patch. This would probably look like this (assuming you had 6 servers from DAG1 in the West Datacenter):
- In our example we are going to patch two servers at a time, starting with Server 5 and Server 6 (of DAG1 in the West Datacenter). Activation block Server 5 and Server 6 so that a failure at this time won’t activate copies of the mailbox databases on those servers.
- Perform a switchover of all databases away from Server 5 and Server 6 to the other four West Datacenter servers in DAG1.
- Patch Server 5 and Server 6.
- Remove activation block from Server 5 and Server 6, activation block Server 3 and Server 4, perform the switchover of all databases from Server 3 and Server 4 to the other four servers in the West Datacenter, and patch Server 3 and Server 4.
- Remove activation block from Server 3 and Server 4, activation block Server 1 and Server 2, perform the switchover of all databases from Server 1 and Server 2 to the other four servers in the West Datacenter, and patch Server 1 and server 2.
- Remove activation block from Server 1 and Server 2, and redistribute your databases evenly across all of the DAG1 West Datacenter servers.
- Once you have patched all servers from DAG1 in the West Datacenter and evenly distributed your databases, you can then add all of the West Datacenter DAG1 servers back into the West Datacenter load-balanced array, completing the patch of the West Datacenter Exchange servers.
Impact(s) of this process:
- While you are patching, it is probable that your site resilience stance will be lower. Think about the scenario where you have a datacenter failure while the servers in the other datacenter are in the process of being patched. If half of your servers have been patched, then this could cause a performance issue in the case where the “passive” datacenter needs to be activated, or it could add time to the activation process while other server patches are completed.
Conclusion
Most of this isn’t “rocket science” – it is just something to think about. We have to be aware that in some instances, especially in those very small environments (small orgs or branch offices), we might want to look at another solution such as virtualizing the whole thing and using Windows NLB instead of using the multi-role servers. This goes back to one of the first things I said – it is all driven by the requirements. If you don’t need mailbox resiliency, don’t deploy a DAG. If your requirements drive you away from the multi-role server, don’t hesitate to go with roles broken out onto separate servers. Just make sure that you make these decisions with your eyes open – understand the implications of everything right down to how you will patch these servers once they have been deployed!
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.