- Home
- Exchange
- Exchange Team Blog
- Exchange Server 2007 High Availability Storage Considerations
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Introduction
Note: for more comprehensive coverage of Exchange 2007 storage please see this blog post:
http://msexchangeteam.com/archive/2007/01/15/432199.aspx
This is the second of a four-part blog on the features in Exchange Server 2007 that are designed to increase availability, and the hardware strategies you can use to increase fault tolerance, service availability and service continuity. Over the next few months I'll be addressing other Exchange 2007 storage best practices in two upcoming blogs:
- Exchange 2007 Backup and Restore Mechanisms
- This focuses on the features and strategies you can use to backup and restore your Exchange 2007 data.
- Exchange 2007 Storage Planning, Configuration, and Validation
- This will build upon the three prior blogs and tie everything together to outline our recommendations on how the storage solution should be configured, validated, and monitored.
In my first blog, Exchange 2007 Server Roles & Disk I/O, I focused on the new features in Exchange 2007 that impact storage. Server roles were briefly talked about, and I introduced the new log shipping functionality used by continuous replication. The focus of this blog are three high-availability features in Exchange 2007:
- Local Continuous Replication (LCR)
- Cluster Continuous Replication (CCR)
- Single Copy Clusters (SCC)
Continuous Replication Overview
Continuous replication is a new Exchange 2007 feature where the storage group's database and log files are copied to a secondary location. The storage group being accessed by clients contains the active copy of the database, and the storage group in the secondary location contains the passive copy of the database.
As new transaction logs are closed, or filled up, they are copied to that secondary location, validated, and then replayed into the copy of the database. The net effect is to provide you with a backup of the database that has already been restored to a mountable location before a disaster happens. This backup will be up to-date with all (or nearly all) transaction log replay already done. If the primary database is destroyed or unavailable, you can be up and running on the secondary copy within minutes.
To support continuous replication, transaction log file size is now 1 MB in Exchange 2007. In previously versions of Exchange, transaction log files were 5 MB.
Storage Terminology
Throughout this blog series, I'll be discussing storage solutions quite a bit. To ensure a common frame of reference, I recommend that you familiarize yourself with the following terms, which are from http://en.wikipedia.org:
- Logical Unit Number (LUN) In computer storage, a logical unit number or LUN is an address for an individual disk drive and by extension, the disk device itself. The term originated in the SCSI protocol as a way of differentiating individual disk drives within a common SCSI target device like a disk array. The term has become common in storage area networks (SAN) and other enterprise storage fields. Today, LUNs are normally not entire disk drives but rather virtual partitions (or volumes) of a RAID set.
- Serial Attached SCSI (SAS) SAS is a serial communication protocol for computer storage devices. It is designed for the corporate and enterprise market as a replacement for SCSI, allowing for much higher speed data transfers than previously available, and is backwards-compatible with SATA. As the name suggests, SAS uses serial communication instead of the parallel method found in traditional SCSI devices, but still uses SCSI commands for interacting with SAS devices.
- Internet SCSI (iSCSI) In the context of computer storage, iSCSI allows a machine to use an iSCSI initiator to connect to remote targets such as disks and tape drives on an IP network for block level I/O. iSCSI protocol uses TCP/IP for its data transfer. Unlike other network storage protocols, such as Fibre Channel (which is the foundation of most SANs), it requires only the simple and ubiquitous Ethernet interface (or any other TCP/IP-capable network) to operate. This enables low-cost centralization of storage without all of the usual expense and incompatibility normally associated with Fibre Channel storage area networks.
Continuous Replication Design Considerations
Isolated Storage
In order to achieve storage resiliency, it is recommended that the passive copy be placed on a storage array that is completely isolated from the active copy's storage array. Isolating the arrays from one another also provides the flexibility to use a variety of storage solutions. If the storage solutions used by the active copy and the passive copy are isolated from each other than your storage solutions don't even need to be the same type or brand. For example, the active copy could be housed on SAS storage, and the passive copy could be housed on iSCSI storage. Regardless of the storage solution(s) you choose, we do recommend that you use storage controllers with battery-backed caching.
Performance
We recommend that you size the active and passive storage solutions equivalently. The purpose of the passive copy to provide a quick switch to the passive copy of the data in the event something catastrophic happens to the active copy. In the case of LCR, the activation is manual, and in the case of CCR, activation is automatic. The storage solution used by the passive copy should be sized both in terms of performance and capacity to handle the production load in the event of a failure.
Legacy streaming backups can be performed against the active copy; but with VSS, you can backup either the active copy or the passive copy. Backing up from the passive copy with a software snapshot is available on any storage type and removes the I/O overhead on the storage for the active copy, assuming you isolate the active and passive copies on separate storage.
Storage Options
Without continuous replication, a storage failure requires you to restore from backup media. As a result, very fast, expensive, and resilient storage devices are typically used. When using shared storage and VSS clones for fast recovery, the solutions often have two or three copies or clones of the data. Continuous replication provides storage resiliency and using it only requires you to store a single copy of the data on disk. With continuous replication, restoration from backup is no longer your first line of defense, and you can make VSS backups from the replica instead of from the live database. Thus, continuous replication not only makes recovery more resilient and faster, but can also reduce transactional I/O requirements, making other storage options, such as direct attached SAS, iSCSI, and single path fiber channel feasible. You may also be able to implement a much less expensive backup solution, because fast restoration from backup is now your second line of defense instead of your primary recovery strategy.
Regardless of your storage solution look you should refer to a vendor's stated best practices for Exchange storage. In the case of solutions submitted to the ESRP program you can reference the Vendors submission at http://www.microsoft.com/technet/prodtechnol/exchange/2003/esrp.mspxge. By selecting a solution on the ESRP program you can ensure that the solution has been validated by the vendor and reviewed by Microsoft. Of course a customer should always test their implementations prior to implementation in production to ensure that the configuration is not impacted by environmental dependencies that the standard tests can not account for and finally you should make sure that the entire solution is properly monitored.
Continuous Replication Availability Considerations
LUN Design
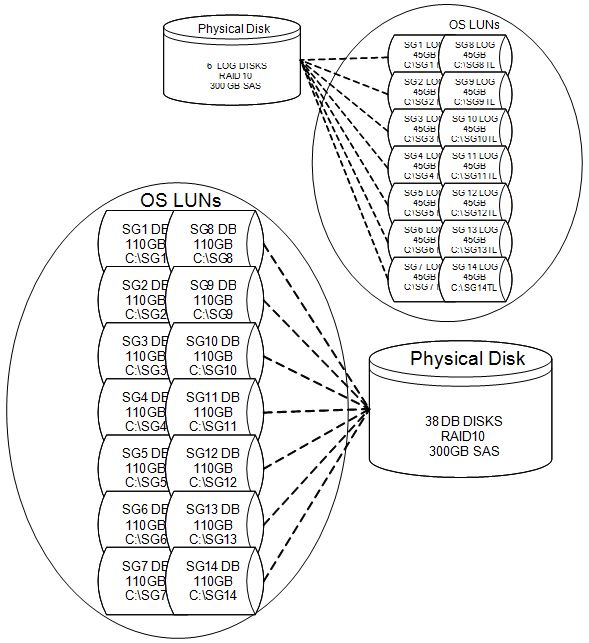
When using continuous replication, each storage group can only contain a single database. As a result, each storage group will optimally use 4 LUNs. Each copy of the database will use one LUN and each set of transaction log files (the set for the active copy and the set for the passive copy) will also use one LUN.
When creating LUNs, it is a best practice to configure the storage as individual LUNs at the hardware level, and to not create multiple logical partitions of a LUN within the operating system. In addition, it is a best practice to separate the transaction logs and databases by storing them on separate physical disks. This increases fault tolerance as losing both your transaction logs and databases in the same storage group can result in extended down time, or the loss of important data. We recommend that you separate the active and passive LUNs on entirely different storage arrays, using different controllers or HBAs, to eliminate the storage as a single point of failure.
LCR
When using LCR, your storage design should maximize fault tolerance by using separate storage controllers on different PCI buses. Continuous replication is your first line of defense in the event of a catastrophic failure; however a single failed disk should not be classified as catastrophic. Every LUN should use a RAID level greater than RAID0 that is built into a storage controller that has a battery-backed cache.

Continuous Replication Performance Considerations
LUN Design
We recommend that you design the storage for your passive copy to match the storage for your active copy in terms of both capacity and performance. The passive copy's storage is the first line of defense in the event of a catastrophic failure of the active copy's storage. Placing log and database LUNs on separate physical disks will keep the database workload consistent. This also ensures that any actions performed against the passive copy's storage, such as a backup; do not impact the active copy's storage.
RAID Selection
RAID10 provides the best performance and is strongly recommended for the LUNs containing the transaction logs. Due to a significant change in database read/write ratios, RAID5 performance in Exchange 2007 is lower than previous versions due to the increase in writes as a percentage of total disk I/O. Often overlooked performance considerations are the behaviors of different RAID levels under both failed disk and array rebuild scenarios. RAID5 and RAID6 suffer from long rebuild times, and significant increased latency, and lowered transactional throughput during failure and rebuild. As a result, we recommend RAID10 for the transaction log LUNs.
Example LUN creation (please click on the thumbnail to view):
I/O Overhead
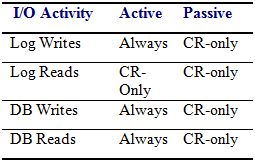
More transactional I/O occurs on the transaction log LUN on servers using continuous replication than on servers not using continuous replication. In previous version of Exchange log files are written, but never read, during normal operation. With continuous replication, each log is read for copy to the replica location This must be taken into consideration when sizing your server. The active copy's transaction log, which uses sequential writes, must also read the log after it has been closed and then copy it to the passive copy's transaction log inspection folder. The log must then be inspected at the passive copy's location and then moved to its final destination on the passive copy's LUN. Finally the log is read and replayed into the passive copy of the database. Both the active and passive transaction log LUNs must perform reads and writes, in contrast to the nearly 100% sequential write activity found on a mailbox server without continuous replication. This change in behavior may require a re-evaluation of the cache settings on your storage controller. Our recommended settings are 25% read and 75% write on a battery-backed storage controller. Both replica and primary log LUNs should be tuned for similar performance, because the replica may suddenly become the primary after a disaster.
LCR Storage Options
Local continuous replication (LCR) enables log replication on a single standalone server. In the event of a catastrophic failure of the active copy of the database or logs, the administrator can quickly manually activate the passive copy. The storage for the passive copy should be completely separate from the storage for the active copy, and to protect against potential driver instability, the storage can be of a different brand and model. To adhere to our best practices:
- Controller cards should be on a different PCI buses
- Active and passive storage LUNs should be on different arrays.
- Example: Primary on SAS and Replica on iSCSI storage.
- Example: Primary on SAS "array 1" and Replica on SAS "array 2".
For a demo of LCR please go here.
CCR Storage Options
With cluster continuous replication (CCR) the second copy of data is stored on the passive node in the same cluster as the active node. Since storage is not shared, you can choose servers listed in the Servers category of the Windows Server Catalog. Unlike single copy clusters, which require a solution that is listed in the Cluster category, CCR only requires servers in the Servers category.
CCR, which includes both automated failover and failback, provides higher availability than LCR. By storing the passive copy on a completely different server, the operational impact to the active copy is decreased, and you have fault tolerance on the server. VSS backups can also be taken from the passive node.
For a demo of CCR please go here.
Geographically-Dispersed Deployment
In a geographically-dispersed CCR deployment, the passive copy can be on a node that is in a different physical location than the active copy, thereby providing site resiliency. Guidelines in our replication document apply, yet the pull technology means high latency will not impact the user experience. This is in sharp contrast to the geographically dispersed cluster where synchronous replication latency does impact the live production LUN. The replication process may run behind, increasing the amount of time the primary and the secondary copy are out of sync. If a disaster occurs on the primary, any mail that had not yet replicated, may be recovered from the Hub Transport servers if it is still available. Proper Hub Transport sizing and configuration is required to ensure that segment of time mail is stored exceeds the projected downtime of the active copy.
Single Copy Cluster (SCC)
Exchange 2003 servers that utilize Windows Clustering use shared storage such as fiber channel or iSCSI SANs. In Exchange 2007 Windows Clustering with shared storage is designated Single Copy Cluster (SCC). This is to help differentiate it from CCR, which uses Windows Clustering, but does not use shared storage for Exchange databases and log files. The storage is local to each node in the cluster. With SCC, all of the hardware, including the disks used for Exchange data, must be listed in the Cluster category of the Windows Server Catalog, and there are a few special considerations for backup. With CCR, the disks used for Exchange databases are local to each system and are not controlled or failed over as part of the cluster. This allows you much greater flexibility.
On a single copy cluster, some administrators use streaming backup to disk, and then fail over the backup LUNs to a passive node which offloads a secondary backup process to tape. VSS solutions require a backup server to mount the volume shadow copy to run checksum integrity. SCC provides redundancy for the server, but not for storage. CCR allows you to simplify backup administration and offload backup IO demands completely to the passive replica server.
Geographically-Dispersed Single Copy Cluster
A clustered Exchange server using shared storage has the same fundamental storage considerations as a stand alone server. In addition, a geographically-dispersed single copy cluster must be on the geographically-dispersed cluster list in the Windows Server Catalog to be fully supported. When using synchronous replication, disk latency on the production LUNs can be artificially increased by the replication process. But CCR deployment has no latency impact on the production database LUNs. More details on can be found in Deployment Guidelines for Exchange Server Multi-Site Data Replication.
Summary
Continuous replication provides service availability and service continuity for an Exchange 2007 mailbox server, without the cost and complexity of a shared storage cluster. VSS and continuous replication are features that assist in enabling larger mailboxes and databases because they offer fast recovery in the event of a storage failure. It is important to maximize the benefits of continuous replication by placing active copy of data and the passive copy of data on separate storage. While the pool of possible storage solutions will grow with continuous replication, the importance of validating and monitoring your storage solution remain the same.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.