- Home
- Exchange
- Exchange Team Blog
- Database Maintenance in Exchange 2010
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Over the last several months there has been significant chatter around what is background database maintenance and why is it important for Exchange 2010 databases. Hopefully this article will answer these questions.
What maintenance tasks need to be performed against the database?
The following tasks need to be routinely performed against Exchange databases:
Database Compaction
The primary purpose of database compaction is to free up unused space within the database file (however, it should be noted that this does not return that unused space to the file system). The intention is to free up pages in the database by compacting records onto the fewest number of pages possible, thus reducing the amount of I/O necessary. The ESE database engine does this by taking the database metadata, which is the information within the database that describes tables in the database, and for each table, visiting each page in the table, and attempting to move records onto logically ordered pages.
Maintaining a lean database file footprint is important for several reasons, including the following:
- Reducing the time associated with backing up the database file
- Maintaining a predictable database file size, which is important for server/storage sizing purposes.
Prior to Exchange 2010, database compaction operations were performed during the online maintenance window. This process produced random IO as it walked the database and re-ordered records across pages. This process was literally too good in previous versions – by freeing up database pages and re-ordering the records, the pages were always in a random order. Coupled with the store schema architecture, this meant that any request to pull a set of data (like downloading items within a folder) always resulted in random IO.
In Exchange 2010, database compaction was redesigned such that contiguity is preferred over space compaction. In addition, database compaction was moved out of the online maintenance window and is now a background process that runs continuously.
Database Defragmentation
Database defragmentation is new to Exchange 2010 and is also referred to as OLD v2 and B+ tree defragmentation. Its function is to compact as well as defragment (make sequential) database tables that have been marked/hinted as sequential. Database defragmentation is important to maintain efficient utilization of disk resources over time (make the IO more sequential as opposed to random) as well as to maintain the compactness of tables marked as sequential.
You can think of the database defragmentation process as a monitor that watches other database page operations to determine if there is work to do. It monitors all tables for free pages, and if a table gets to a threshold where a significant high percentage of the total B+ Tree page count is free, it gives the free pages back to the root. It also works to maintain contiguity within a table set with sequential space hints (a table created with a known sequential usage pattern). If database defragmentation sees a scan/pre-read on a sequential table and the records are not stored on sequential pages within the table, the process will defrag that section of the table, by moving all of the impacted pages to a new extent in the B+ tree. You can use the performance counters (mentioned in the monitoring section) to see how little work database defragmentation performs once a steady state is reached.
Database defragmentation is a background process that analyzes the database continuously as operations are performed, and then triggers asynchronous work when necessary. Database defragmentation is throttled under two scenarios:
- The max number of outstanding tasks This keeps database defragmentation from doing too much work the first pass if massive change has occurred in the database.
- A latency throttle of 100ms When the system is overloaded, database defragmentation will start punting defragmentation work. Punted work will get executed the next time the database goes through that same operational pattern. There's nothing that remembers what defragmentation work was punted and goes back and executes it once the system has more resources.
Database Checksumming
Database checksumming (also known as Online Database Scanning) is the process where the database is read in large chunks and each page is checksummed (checked for physical page corruption). Checksumming’s primary purpose is to detect physical corruption and lost flushes that may not be getting detected by transactional operations (stale pages).
With Exchange 2007 RTM and all previous versions, checksumming operations happened during the backup process. This posed a problem for replicated databases, as the only copy to be checksummed was the copy being backed up. For the scenario where the passive copy was being backed up, this meant that the active copy was not being checksummed. So in Exchange 2007 SP1, we introduced a new optional online maintenance task, Online Maintenance Checksum (for more information, see Exchange 2007 SP1 ESE Changes – Part 2).
In Exchange 2010, database scanning checksums the database and performs post Exchange 2010 Store crash operations. Space can be leaked due to crashes, and online database scanning finds and recovers lost space. Database checksum reads approximately 5 MB per second for each actively scanning database (both active and passive copies) using 256KB IOs. The I/O is 100 percent sequential. The system in Exchange 2010 is designed with the expectation that every database is fully scanned once every seven days.
If the scan takes longer than seven days, an event is recorded in the Application Log :
Event ID: 733
Event Type: Information
Event Source: ESE
Description: Information Store (15964) MDB01: Online Maintenance Database Checksumming background task is NOT finishing on time for database 'd:\mdb\mdb01.edb'. This pass started on 11/10/2011 and has been running for 604800 seconds (over 7 days) so far.
If it takes longer than seven days to complete the scan on the active database copy, the following entry will be recorded in the Application Log once the scan has completed:
Event ID: 735
Event Type: Information
Event Source: ESE
Description: Information Store (15964) MDB01 Database Maintenance has completed a full pass on database 'd:\mdb\mdb01.edb'. This pass started on 11/10/2011 and ran for a total of 777600 seconds. This database maintenance task exceeded the 7 day maintenance completion threshold. One or more of the following actions should be taken: increase the IO performance/throughput of the volume hosting the database, reduce the database size, and/or reduce non-database maintenance IO.
In addition, an in-flight warning will also be recorded in the Application Log when it takes longer than 7 days to complete.
In Exchange 2010, there are now two modes to run database checksumming on active database copies:
- Run in the background 24×7 This is the default behavior. It should be used for all databases, especially for databases that are larger than 1TB. Exchange scans the database no more than once per day. This read I/O is 100 percent sequential (which makes it easy on the disk) and equates to a scanning rate of about 5 megabytes (MB)/sec on most systems. The scanning process is single threaded and is throttled by IO latency. The higher the latency, the more database checksum slows down because it is waiting longer for the last batch to complete before issuing another batch scan of pages (8 pages are read at a time).
- Run in the scheduled mailbox database maintenance process When you select this option, database checksumming is the last task. You can configure how long it runs by changing the mailbox database maintenance schedule. This option should only be used with databases smaller than 1 terabyte (TB) in size, which require less time to complete a full scan.
Regardless of the database size, our recommendation is to leverage the default behavior and not configure database checksum operations against the active database as a scheduled process (i.e., don’t configure it as a process within the online maintenance window).
For passive database copies, database checksums occur during runtime, continuously operating in the background.
Page Patching
Page patching is the process where corrupt pages are replaced by healthy copies. As mentioned previously, corrupt page detection is a function of database checksumming (in addition, corrupt pages are also detected at run time when the page is stored in the database cache). Page patching works against highly available (HA) database copies. How a corrupt page is repaired depends on whether the HA database copy is active or passive.
Page patching process
| On active database copies | On passive database copies |
|
|
Page Zeroing
Database Page Zeroing is the process where deleted pages in the database are written over with a pattern (zeroed) as a security measure, which makes discovering the data much more difficult.
With Exchange 2007 RTM and all previous versions, page zeroing operations happened during the streaming backup process. In addition since they occurred during the streaming backup process they were not a logged operation (e.g., page zeroing did not result in the generation of log files). This posed a problem for replicated databases, as the passive copies never had its pages zeroed, and the active copies would only have it pages zeroed if you performed a streaming backup. So in Exchange 2007 SP1, we introduced a new optional online maintenance task, Zero Database Pages during Checksum (for more information, see Exchange 2007 SP1 ESE Changes – Part 2). When enabled this task would zero out pages during the Online Maintenance Window, logging the changes, which would be replicated to the passive copies.
With the Exchange 2007 SP1 implementation, there is significant lag between when a page is deleted to when it is zeroed as a result of the zeroing process occurring during a scheduled maintenance window. So in Exchange 2010 SP1, the page zeroing task is now a runtime event that operates continuously, zeroing out pages typically at transaction time when a hard delete occurs.
In addition, database pages can also be scrubbed during the online checksum process. The pages targeted in this case are:
- Deleted records which couldn’t be scrubbed during runtime due to dropped tasks (if the system is too overloaded) or because Store crashed before the tasks got to scrub the data;
- Deleted tables and secondary indices. When these get deleted, we don’t actively scrub their contents, so online checksum detects that these pages don’t belong to any valid object anymore and scrubs them.
For more information on page zeroing in Exchange 2010, see Understanding Exchange 2010 Page Zeroing.
Why aren’t these tasks simply performed during a scheduled maintenance window?
Requiring a scheduled maintenance window for page zeroing, database defragmentation, database compaction, and online checksum operations poses significant problems, including the following:
- Having scheduled maintenance operations makes it very difficult to manage 24x7 datacenters which host mailboxes from various time zones and have little or no time for a scheduled maintenance window. Database compaction in prior versions of Exchange had no throttling mechanisms and since the IO is predominantly random, it can lead to poor user experience.
- Exchange 2010 Mailbox databases deployed on lower tier storage (e.g., 7.2K SATA/SAS) have a reduced effective IO bandwidth available to ESE to perform maintenance window tasks. This is an issue because it means that IO latencies will increase during the maintenance window, thus preventing the maintenance activities to complete within a desired period of time.
- The use of JBOD provides an additional challenge to the database in terms of data verification. With RAID storage, it's common for an array controller to background scan a given disk group, locating and re-assigning bad blocks. A bad block (aka sector) is a block on a disk that cannot be used due to permanent damage (e.g. physical damage inflicted on the disk particles). It's also common for an array controller to read the alternate mirrored disk if a bad block was detected on the initial read request. The array controller will subsequently mark the bad block as “bad” and write the data to a new block. All of this occurs without the application knowing, perhaps with just a slight increase in the disk read latency. Without RAID or an array controller, both of these bad block detection and remediation methods are no longer available. Without RAID, it's up to the application (ESE) to detect bad blocks and remediate (i.e., database checksumming).
- Larger databases on larger disks require longer maintenance periods to maintain database sequentiality/compactness.
Due to the aforementioned issues, it was critical in Exchange 2010 that the database maintenance tasks be moved out of a scheduled process and be performed during runtime continuously in the background.
Won’t these background tasks impact my end users?
We’ve designed these background tasks such that they're automatically throttled based on activity occurring against the database. In addition, our sizing guidance around message profiles takes these maintenance tasks into account.
How can I monitor the effectiveness of these background maintenance tasks?
In previous versions of Exchange, events in the Application Log would be used to monitor things like online defragmentation. In Exchange 2010, there are no longer any events recorded for the defragmentation and compaction maintenance tasks. However, you can use performance counters to track the background maintenance tasks under the MSExchange Database ==> Instances object:
| Counter | Description |
| Database Maintenance Duration | The number of seconds that have passed since the maintenance started for this database. If the value is 0, maintenance has been finished for the day. |
| Database Maintenance Pages Bad Checksums | The number of non-correctable page checksums encountered during a database maintenance pass |
| Defragmentation Tasks | The count of background database defragmentation tasks that are currently executing |
| Defragmentation Tasks Completed/Sec | The rate of background database defragmentation tasks that are being completed |
You'll find the following page zeroing counters under the MSExchange Database object:
| Counter | Description |
| Database Maintenance Pages Zeroed | Indicates the number of pages zeroed by the database engine since the performance counter was invoked |
| Database Maintenance Pages Zeroed/sec | Indicates the rate at which pages are zeroed by the database engine |
How can I check whitepace in a database?
You will need to dismount the database and use ESEUTIL /MS to check the available whitespace in a database. For an example, see http://technet.microsoft.com/en-us/library/aa996139(v=EXCHG.65).aspx (note that you have to multiply the number of pages by 32K).
Note that there is a status property available on databases within Exchange 2010, but it should not be used to determine the amount of total whitespace available within the database:
Get-MailboxDatabase MDB1 -Status | FL AvailableNewMailboxSpace
AvailableNewMailboxSpace tells you is how much space is available in the root tree of the database. It does not factor in the free pages within mailbox tables, index tables, etc. It is not representative of the white space within the database.
How can I reclaim the whitespace?
Naturally, after seeing the available whitespace in the database, the question that always ensues is – how can I reclaim the whitespace?
Many assume the answer is to perform an offline defragmentation of the database using ESEUTIL. However, that's not our recommendation. When you perform an offline defragmentation you create an entirely brand new database and the operations performed to create this new database are not logged in transaction logs. The new database also has a new database signature, which means that you invalidate the database copies associated with this database.
In the event that you do encounter a database that has significant whitespace and you don't expect that normal operations will reclaim it, our recommendation is:
- Create a new database and associated database copies.
- Move all mailboxes to the new database.
- Delete the original database and its associated database copies.
A terminology confusion
Much of the confusion lies in the term background database maintenance. Collectively, all of the aforementioned tasks make up background database maintenance. However, the Shell, EMC, and JetStress all refer to database checksumming as background database maintenance, and that's what you're configuring when you enable or disable it using these tools.
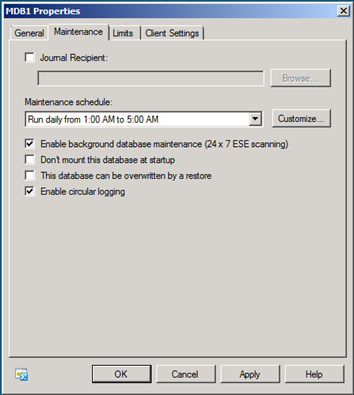
Figure 1: Enabling background database maintenance for a database using EMC
Enabling background database maintenance using the Shell:
Set-MailboxDatabase -Identity MDB1 -BackgroundDatabaseMaintenance $true
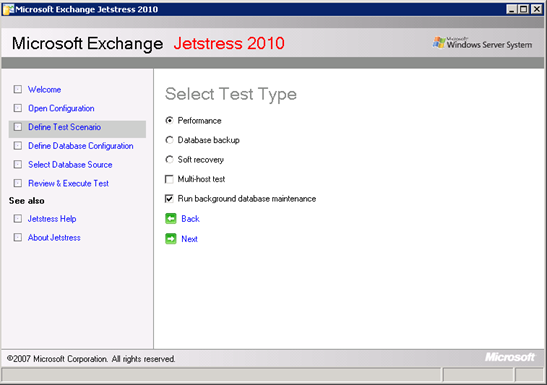
Figure 2: Running background database maintenance as part of a JetStress test
My storage vendor has recommended I disable Database Checksumming as a background maintenance task, what should I do?
Database checksumming can become an IO tax burden if the storage is not designed correctly (even though it's sequential) as it performs 256K read IOs and generates roughly 5MB/s per database.
As part of our storage guidance, we recommend you configure your storage array stripe size (the size of stripes written to each disk in an array; also referred to as block size) to be 256KB or larger.
It's also important to test your storage with JetStress and ensure that the database checksum operation is included in the test pass.
In the end, if a JetStress execution fails due to database checksumming, you have a few options:
- Don’t use striping Use RAID-1 pairs or JBOD (which may require architectural changes) and get the most benefit from sequential IO patterns available in Exchange 2010.
- Schedule it Configure database checksumming to not be a background process, but a scheduled process. When we implemented database checksum as a background process, we understood that some storage arrays would be so optimized for random IO (or had bandwidth limitations) that they wouldn't handle the sequential read IO well. That's why we built it so it could be turned off (which moves the checksum operation to the maintenance window).
If you do this, we do recommend smaller database sizes. Also keep in mind that the passive copies will still perform database checksum as a background process, so you still need to account for this throughput in our storage architecture. For more information on this subject see Jetstress 2010 and Background Database Maintenance.
- Use different storage or improve the capabilities of the storage Choose storage which is capable of meeting Exchange best practices (256KB+ stripe size).
Conclusion
The architectural changes to the database engine in Exchange Server 2010 dramatically improve its performance and robustness, but change the behavior of database maintenance tasks from previous versions. Hopefully this article helps your understanding of what is background database maintenance in Exchange 2010.
Ross Smith IV
Principal Program Manager
Exchange Customer Experience
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.