- Home
- Security, Compliance, and Identity
- Core Infrastructure and Security Blog
- Troubleshooting Adventure: A Real Life Memory Pool Leak
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
First published on TechNet on Dec 29, 2013
Hi this is Jerry Devore with my first blog contribution. I am dedicated Premier Field Engineer specializing in Active Directory for a couple enterprise customers in the mid-west. Dedicated PFEs are generally embedded with Premier customer’s architects and operational staff with the primary objective of understanding their environment so we can provide proactive guidance around optimizing solutions and ensuring maximum uptime. However, we also play a reactive role when our customers are in fire fighter mode. Today I would like to share recent example of a 5 alarm outage I recently encountered.
The customer’s Exchange team contacted me because their Exchange CAS servers were randomly failing to respond to client requests. When the issue occurred the impacted server would sometimes recover on its own but most of the time it had to be rebooted in order to restore services. In diagnosing the issue they had confirmed two things. 1 - This problem showed up in the same month the Active Directory team raised the Forest Functional level to 2008 R2. 2 - The application logs contain 2070 events indicating the domain controllers being unresponsive. Therefore Active Directory is responsible is bringing down the Exchange environment!

Now that this was an Active Directory problem my first step was to check the vitals of the four domain controllers in the data center. The event logs were clean, the processors were not running hot and there was plenty of free memory available. Given only one Exchange sever was tipping over at a time I had a hard time accepting that Active Directory was the culprit. However, I have eaten enough crow over my 17 years in IT to know not to rule out anything too early so I forged ahead.
The next step I took was to verify there truly was a Domain Controller response issue encountered by the Exchange servers. I grabbed the performance logs from the most recently afflicted CAS server and loaded up the counter for MSExchange ADAccess LDAP Search Time . Sure enough there was a huge spike in LDAP latency just as the server was going south.

MSExchange AD ADAccess LDAP Search Time
Before going any further I checked the vitals of the Exchange server. First up Processor utilization. Hmmm…. This is strange the processors started to cool down a few minutes before Exchange stopped servicing requests.

% Processor Time _Total
To make sure there was not a bus issue creating a bottleneck to the processors I checked the Processor Queue length of the CAS server. Nope, a brief spike to 7 is nothing to be concerned about.

System Processor Queue
Being disk bound can bring Exchange to its knees so I loaded up the disk counters. OK.. This is strange. The disk counters stopped collecting as the server began to struggle.
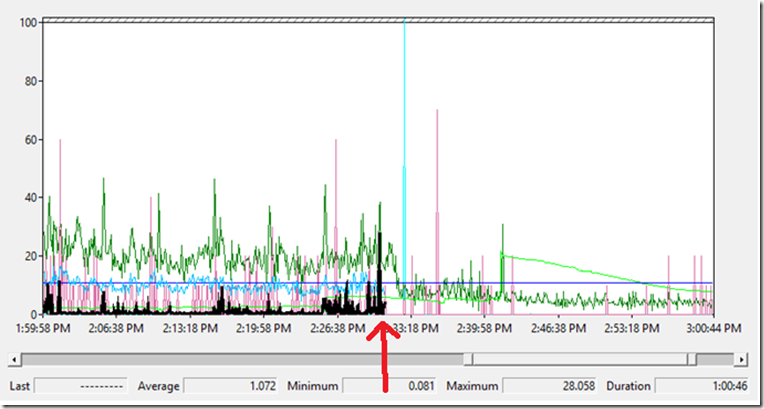
% Disk Time _Total
Maybe the Network card is saturated and that is why the connection to the domain controller failed so I added in the counter for Bytes Total/Sec on the CAS server and found another clue. The network counters dropped out the same time as the disk counters.

Network Bytes Total/Sec
Checked out processor, disk and network. The remaining key vital sign to check is memory. The Exchange process store.exe is known for using all of the free memory it is can get its hands on. Therefore I did not get too concerned when I loaded the Available MB counter and noticed it did not have much physical memory free. In fact at 2:26 PM some memory became free so it had more available when the outage started than it had earlier in the day.

Available MBytes
It was at this point I started to comb through the System event log of the CAS server and found a 2019 event indicating the NonPaged Pool was depleted at 2:40 PM. This is just not adding up because x64 servers aren’t nearly as limited on NonPaged Pool memory as 32 bit servers. But I better check it out anyway.

Hoping to see the answer jump out at me I loaded up the Non Paged Pool Bytes counter but all I found was a flat line that did not show a drastic change in NonPaged Pool. Maybe the Event 2019 was a fluke or the result of the server taking a nose dive.
Then it dawned on me that I should run 1.1004e+010 through a calculator to figure just how much NonPaged Pool is in use. Holy cow that is 10.2 GB!!! x64 or not that is ton of memory tied up by the kernel. Better look at some SCOM data to see how long that has been going on.

Non Paged Pool Bytes
Now we are getting somewhere. The stair step pattern in the SCOM chart for NonPaged pool is exactly what we would expect to see with a memory leak overtime. The one hour worth of data in the Perfmon capture was simply too short to reflect the growth.

Now that we had confirmed an issue with NonPaged pool it was time to determine the source of the leak I so fired up Poolmon and saw something very similar to the following.

The SmMs tag was by far the top consumer of Non Page Pool memory. With a little help from Bing I discovered the SmMs tag mapped to a leak in the Mrxsmb20.sys driver. With the hotfix applied we monitored the NonPaged Pool usage and confirmed this issue has been resolved.
In concluding this riveting “Who Done It” story I would like point out a few things that might help you during your next fire fight.
· When troubleshooting problems that span support groups keep an open mind and don’t just deem it some else’s problem. If you can facilitate cooperation between teams and get the problem resolved you will add to your technical skills and gain respect in your organization.
· Bench mark your environment and be familiar with what are healthy and unhealthy performance counter values. Also retain historical performance data so you can determine when a problem started.
· Put your Office Space “ Jump to Conclusions Mat ” away and dig into the diagnostic data. For example comb through the Performance Monitor captures and event logs to rebuild the timeline. That way you can determine the order of events and start to make sense of some mixed signals.
If you want to improve your performance troubleshooting skills I highly recommend our Vital Signs Workshop . It is a 3 day class for Premier customers which takes a deep dive on concepts related to Physical Memory, Virtual Memory, Network performance, Disk performance and Processor utilization. Many people have told me it is hands down the best technical training class they have ever attended. Talk to your TAM if you would like to know when it is coming to your area.
Jerry “Fireman” Devore, Microsoft PFE
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.