- Home
- Azure
- Azure Compute
- Creating Reliability Through Chaos With Azure VMs and Gremlin
Creating Reliability Through Chaos With Azure VMs and Gremlin
- Subscribe to RSS Feed
- Mark Discussion as New
- Mark Discussion as Read
- Pin this Discussion for Current User
- Bookmark
- Subscribe
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jan 04 2019 11:45 AM
Creating Reliability Through Chaos With Azure VMs and Gremlin
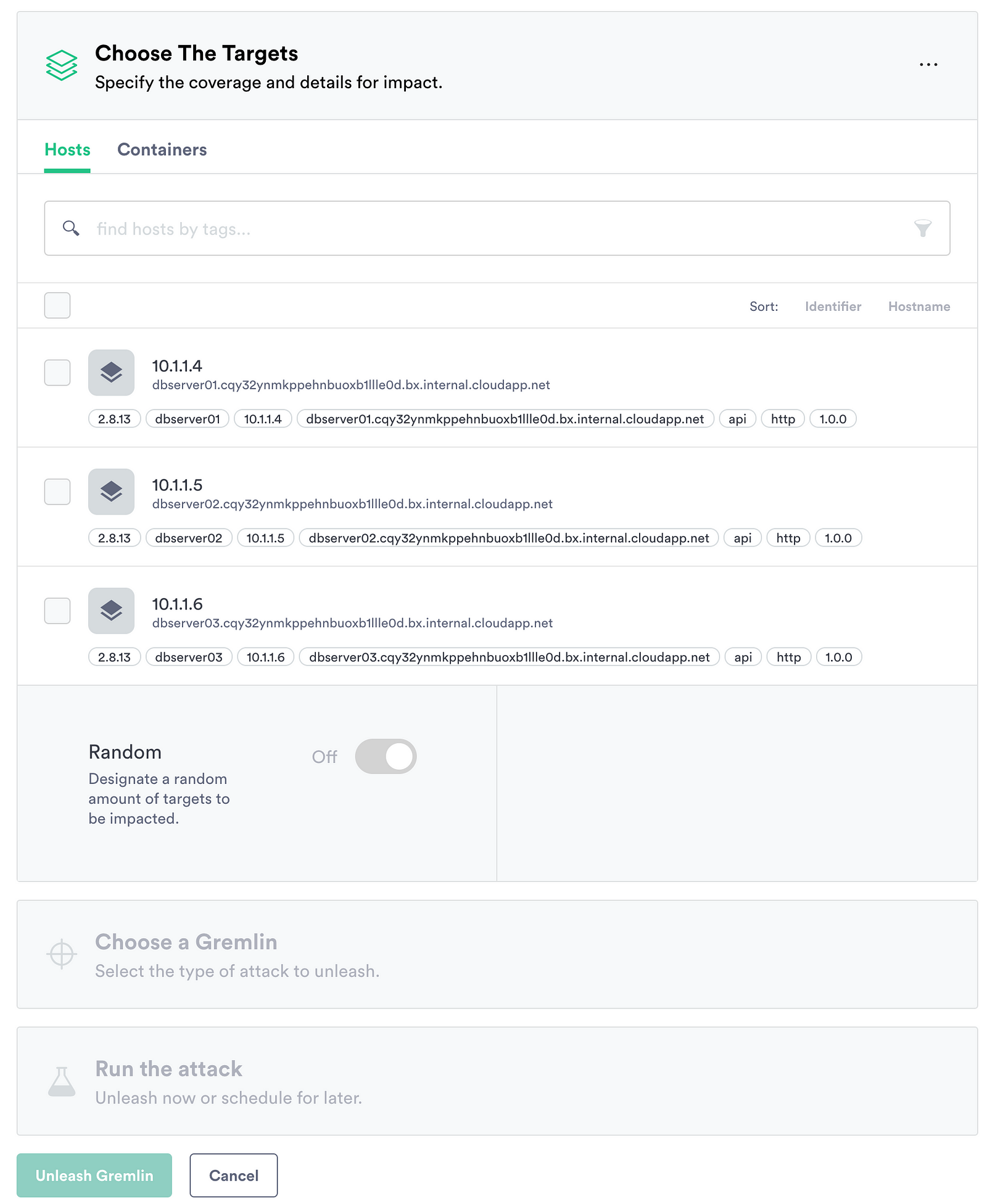
The idea of “Chaos Engineering” isn’t just about putting faith in a provider to stay online, it’s finding ways to simulate failure in order to determine that you’ll withstand an outage of any kind within your application. This means that if a number of your app servers take on a large portion of traffic and are highly CPU taxes, you’ll know how to properly scale your application to withstand it. If portions of your application infrastructure were to take on a massive amount of packet loss, how does your team respond?
Chaos engineering helps answer some of these questions by allowing you to simulate the possibilities of what a failure may look like in your production environment. For some, using tools like Chaos Monkey has helps produce load and service failures to help create attack simulations. Lately I have been working with Gremlin, which acts as a “Chaos-as-a-Service” through a simple client-server model.