- Home
- SQL Server
- SQL Server Integration Services (SSIS) Blog
- Data Preparation for Azure Machine Learning using SSIS
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Microsoft Azure Machine Learning enables businesses to perform cloud-based predictive analytics to understand what their data means. Machine learning algorithms learn from data. It is critical that you feed them the right data for the problem you want to solve. Such data can be business transactional data or sensitive business data that is either on-premises or on the cloud. Also, even if you have good data, you need to make sure that it is in a useful scale and format. The more disciplined you are in handling of data, the more consistent and better results you are like likely to achieve. Therefore, data preparation process is critical for machine learning. In general, data preparation can be summarized into three steps:
- Select Data
- Preprocess Data
- Transform Data
Today, Azure Machine Learning studio already provide ways for you to select data , preprocess data and transform data .
In this blog, we will show you how you can unleash the power of SQL Server Integration Service (SSIS) with SQL Server Integration Services Feature Pack for Azure in your data preparation process for Azure Machine Learning, allowing you to select more data sources, providing more options for your data preprocessing and transformation.
Select Data
Many businesses have multiple different data sources within their IT infrastructure. Some data is in relational databases such as SQL Server, Oracle or Teradata etc. while some is on files like Excel, XML, flat files or azure blob files in the cloud. Selecting a subset of all available data that is relevant to your machine learning algorithms is a key step in the data preparation process. SQL Server Integration Service (SSIS) provides many source connectivity such as Azure Blob , ODBC , OLE DB , ADO NET , Excel , Flat File , Teradata/Oracle , OData and more for you to connect to different data sources and select the subset of available data.
Preprocess Data
After you have selected your data, your next step is to preprocess the data and get the selected data into the state that you can work with. Usually, the data preprocessing steps are formatting, cleansing, and sampling.
- Formatting – Data from various sources may not be in a format that is suitable and consistent for you to work with. You can use the Data Flow Source components to pull data from both SQL Server and Oracle database, manipulate it using Integration Services Transformations , then serialize it into certain file format like CSV and store it in the Azure Blob Storage using the Azure Blob Destination where Azure Machine Learning can consume.
- Cleansing – Cleansing not only refers to fixing missing/bad data, but it can also refers to anonymizing and removing sensitive information such as personal identification information (PII) data. You can use the Data Quality Services Cleansing Transformation , Script Component and/or other Integration Services Transformations to correct data or to perform PII data masking and removal.
- Sampling – It is common that you may have far more selected data available than you need for your machine learning algorithms. More data can result in much longer running time and computational requirements. Sometimes it’s better to take a smaller sample of the selected data for your machine learning process to enable faster prototype and testing of your solution. In the SSIS Data Flow , you can add filter in the source components, and/or use transformation components such as Conditional Split to select smaller set of data.
Transform Data
After you have preprocessed the data, the last step you would consider is to transform it. Machine learning algorithm are only as good as the data that is used to train them. Good training data is usually in a form that is optimized for learning and generalization. The process of putting together the data in this optimal format is known in the industry as feature transformation and there are commonly 3 types:
- Scaling – The preprocessed data may contains attributes with mixtures of scales for different quantities such as volume, kilograms or currency signs. You can use Integration Services Transformations to transform and standardize your data in the same scale.
- Decomposition – Sometimes it may be useful to split the data into constituent parts for machine learning training. For example, You can use Integration Services Transformations and/or Script Component to split the address “One Microsoft Way, Redmond, WA, 98052” to create additional features like “Address” (One Microsoft Way), “City” (Redmond), “State” (WA) and “Zip” (98052) such that the learning algorithm can group more disparate transactions together, and discover broader patterns – perhaps some merchant zip codes experience more fraudulent activity than others.
- Aggregation – on the other hand, sometimes it may be more useful to aggregate data to make it more meaningful for your machine learning algorithms. For example there may be data instances for each transactional time a credit card is swiped that could be aggregated into the count for the number of transaction made and you can use Integration Services Transformations and/or Script Component to achieve that as well.
Example: Using SSIS to prepare data for a Credit Cardholder purchase behavior prediction
Build the SSIS Data Flow for data preparation
Assume that you are working with a Cluster Model ( read more about building the Cluster Model in Azure Machine Learning) to predict behaviors of credit cardholders, the model needs to be trained with data of credit card transactions, which is stored in an on-premises SQL Server database.
To prepare the training data, you can build a SSIS package and design its Data Flow using following components:
1) OLE DB Source : extract the “Customer”, “Credit Card”, and “Transaction” tables from SQL Server.
2) Merge Join : join data in the three tables to combine the columns.
3) Conditional Split : filter out the expired data by applying conditions.
4) Script Component : run .Net (C#/VB) code to perform specific transformation on the data. In this case, mask the column which contains customer PII data.
5) Azure Blob Destination : load the integrated, filtered and masked data into Azure Blob Storage, which will be ready for Azure Machine Learning to consume.

As next step, you can deploy the package to SSIS Catalog , and schedule its execution using SQL Agent. It will provide you an operational workflow of preparing data to train the Machine Learning model.
Consume prepared data in Machine Learning experiment
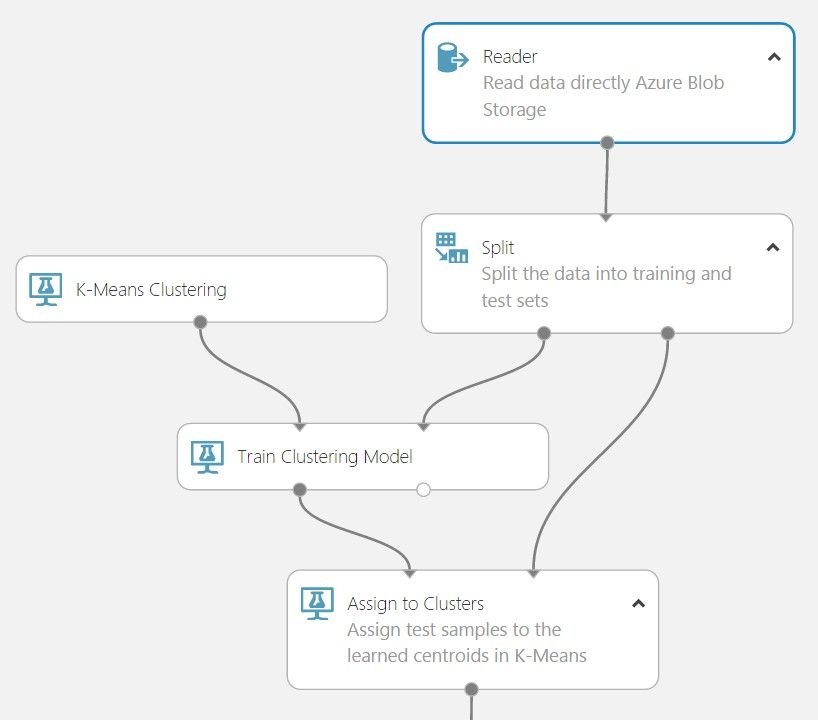
Once the SSIS package has uploaded the prepared data to Azure Blob Storage, you can use the Reader module in Machine Learning Studio to load the data into an experiment. Reader uses this data to create a dataset that can be connected to any other module that supports a dataset on the input port.
Summary
Building an advanced analytics data pipeline with machine learning capabilities is just like building LEGO, you can build it with different patterns and possibilities. Now you can use both the Azure Machine Learning Studio and/or SQL Server Integration Service to perform various steps within the data preparation process. Specifically, SQL Server Integration Service can be your on-premises data preparation solution to connect, select, preprocess and transform data on-premises first before moving the data to Azure for your machine learning experiment!
Try it yourself
To build and run the SSIS package, please download and install:
Microsoft SQL Server Data Tools - Business Intelligence for Visual Studio 2013
Microsoft SQL Server 2014 Integration Services Feature Pack for Azure
Related document:
Doing More With SQL Server Integration Services Feature Pack for Azure
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.