- Home
- Security, Compliance, and Identity
- Core Infrastructure and Security Blog
- Viewing SQL Server Non-Clustered Index Page Contents
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
First published on MSDN on Apr 04, 2013
In this blog post I’ll take a look at what is actually stored in a non-clustered index and (re)introduce you to some tools that you can use for looking at the contents of a given data or index page. Hopefully, by the end of the examples you’ll have a better idea as to what SQL Server is looking at when it is traversing an index and what is stored in the root and intermediate pages of an index.
First, I’ll create a database to use for our scenario. I’ll create a table named NumbersTable and load 40K records into it.
USE master
GO
SET STATISTICS XML OFF
SET STATISTICS IO OFF
SET NOCOUNT ON
GO
IF DB_ID('HeapsDB') IS NOT NULL
BEGIN
ALTER DATABASE HeapsDB
SET SINGLE_USER
WITH
ROLLBACK IMMEDIATE
DROP DATABASE HeapsDB
END
GO
CREATE DATABASE HeapsDB
GO
ALTER DATABASE HeapsDB
SET RECOVERY SIMPLE
GO
USE HeapsDB
GO
CREATE TABLE NumbersTable (
NumberValue BIGINT NOT NULL
,BiggerNumber BIGINT NOT NULL
,CharacterColumn CHAR(50)
)
GO
INSERT INTO NumbersTable (
NumberValue
,BiggerNumber
,CharacterColumn
)
SELECT NumberValue
,NumberValue + 5000000
,LEFT(REPLICATE((CAST(NumberValue AS VARCHAR(50))), 50), 50)
FROM (
SELECT NumberValue = row_number() OVER (
ORDER BY newid() ASC
)
FROM master..spt_values a
CROSS APPLY master..spt_values b
WHERE a.type = 'P'
AND a.number <= 200
AND a.number > 0
AND b.type = 'P'
AND b.number <= 200
AND b.number > 0
) a
Next, cluster the table on the NumberValue column. Notice that I am adding the clustered index as a Primary Key constraint – which is unique. Had a simply added a clustered index to the table and not specified that the clustered index be UNIQUE, then a “uniqueifier” would be added to the key definition to ensure uniqueness. I’ll discuss this “uniqueifier” in a later tip.
I then add a non-clustered index on the BiggerNumber column.
ALTER TABLE NumbersTable ADD CONSTRAINT PK_NumbersTable PRIMARY KEY CLUSTERED (NumberValue) GO CREATE NONCLUSTERED INDEX idx_NumbersTable ON NumbersTable (BiggerNumber) GO
I can use sys.dm_db_index_physical_stats to view the depth of the B-tree non-clustered index. Remember that a non-clustered index contains only a subset of the columns in the base table and is organized in a B-tree structure. These NC indexes allow for very fast searching of data, potentially without needing to access the base table. (For more information regarding the overall structure of a NC Index, see this article: http://msdn.microsoft.com/en-us/library/ms177484(v=sql.105).aspx )
--look at the depth of the trees on the NC index idx_NumbersTable
SELECT page_count
,index_level
,record_count
,index_depth
FROM sys.dm_db_index_physical_stats(db_id(), object_id('NumbersTable'), 2, NULL, 'DETAILED');

I can see that there are 2 levels to this index - a root and the leaf. Had the index stored more rows (or wider rows) then it is possible that there be one or more intermediate levels. However, for simplicity purposes I’m sticking to just two levels for this example.
The root page is always a single page which points to an intermediate level of pages, or in this case simply a leaf level set of pages. The query also indicates that the root page contains 109 records. As it so happens, the leaf level of the index contains 109 pages. Coincidence? I think not! J You see, the root page contains one record pointing to each page in the subordinate (in this case the leaf) level in the index.
If I use the sys.dm_db_database_page_allocations DMV, I can find the page ID for the root page in the index. Note: This functionality existed in previous versions of SQL Server with the DBCC IND command.
In this case, it is page 384.
--look at the linkages for the NC index
SELECT allocated_page_page_id
,next_page_page_id
,previous_page_page_id
,page_level
FROM sys.dm_db_database_page_allocations(db_id(), object_id('NumbersTable'), 2, NULL, 'DETAILED')
WHERE page_type_desc IS NOT NULL
AND page_type_desc = 'INDEX_PAGE'
AND page_level = 1

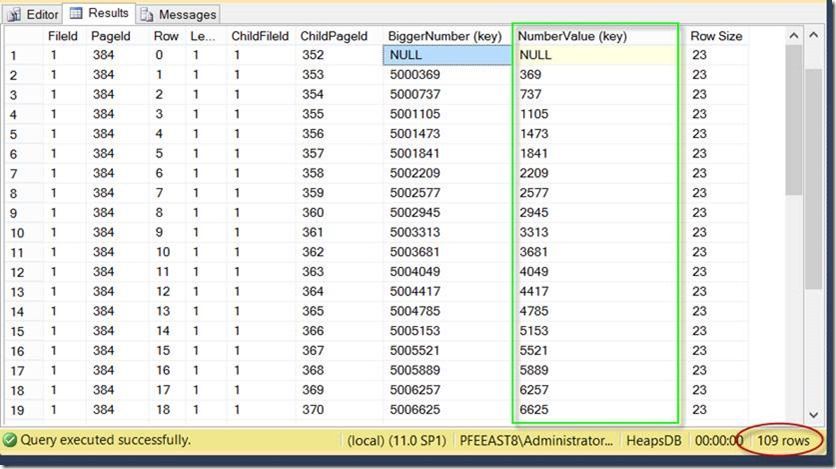
I can then use DBCC PAGE to look at the contents of the index page. Note – since I am using the WITH TABLERESULTS option there is no need to turn on Trace Flag 3604. If you want to view the results from DBCC PAGE without TABLERESULTS, you’ll need to enable that trace flag. Looking at the second resultset from the DBCC PAGE call, I can see that 109 records are returned, along w/ the keys stored in the NC index in the root page. I see that the BiggerNumber column is returned along with the NumberValue column, which is the clustered key on the table. We have to store the clustered key in the root page (and intermediate pages if they existed) in this case because we have to have a way to get to a unique key in the leaf level of the index. Since the NC index isn’t defined as unique, we store the clustered key as well (which is always unique).
Note: We also do not store INCLUDED columns in the root or intermediate levels of a non-clustered index – only the leaf level.
DBCC PAGE(HeapsDB, 1, 384, 3) WITH TABLERESULTS
Running the same example again with a UNIQUE NC index, we can see the difference.
CREATE UNIQUE NONCLUSTERED INDEX idx_NumbersTable ON NumbersTable(BiggerNumber) WITH DROP_EXISTING
Next, find the root page of the new index.
SELECT allocated_page_page_id
,next_page_page_id
,previous_page_page_id
,page_level
FROM sys.dm_db_database_page_allocations(db_id(), object_id('NumbersTable'), 2, NULL, 'DETAILED')
WHERE page_type_desc IS NOT NULL
AND page_type_desc = 'INDEX_PAGE'
AND page_level = 1

And pass the root page, 544 in this case, to the call to DBCC PAGE. I see in this case that the BiggerNumber column is the only column value stored in the root page. I also see that my row size is now 15 bytes, whereas before it was 23 bytes. This 8 byte difference is due to the fact that the absent NumberValue column (the unique clustered key on the table) is a BIGINT, which is 8 bytes in size.
DBCC PAGE(HeapsDB, 1, 544, 3) WITH TABLERESULTS

So, what do these values in the BiggerNumber column actually point to in the root? They point to child pages in the subordinate level in the index. Using this approach, an index traversal can interrogate the values in the root page and determine which pages in the next level of the index need to be accessed. This works for singleton lookups as well as for read-ahead. For example, let’s look at page 512 – which happens to be the first page in the leaf level of the index. From the results above, I can see that ChildPageID has a BiggerNumber key value of NULL. The next record in the root page points to the BiggerNumber key value of 5000369. So –the ChildPage 512 should contain values NULL all the way through 5000368. If we look at DBCC PAGE for 512, we can see all the values it contains:
DBCC PAGE(HeapsDB, 1, 512, 3) WITH TABLERESULTS

In fact, this leaf level page does contain the BiggerNumber key values 5000001 – 5000368. Also, since this is the leaf level there must be a pointer back to the base table (in this case the clustered index). So, that is why the NumberValue column is present.
Hope this helps!
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.