- Home
- Exchange
- Exchange Team Blog
- Demystifying the CAS Array Object - Part 2
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Welcome back! In Demystifying the CAS Array Object - Part 1 we covered these three items to begin demystifying the CASarray object in Exchange Server 2010.
- A CAS array object does not load balance your traffic
- A CAS array object does not service OWA, ECP, EWS, Autodiscover, IMAP, SMTP, or POP
- A CAS array object does not need to be part of your SSL certificate
Here in Part 2 we will cover the following three items, and once and for all lift the fog away from the CAS array object to help you correct existing deployments and/or plan more strategically for future deployments.
- A CAS array object should not be resolvable via DNS by external clients
- A CAS array object should not be configured or changed after creating Exchange Server 2010 mailbox databases and moving mailboxes into the databases
- A CAS array object should be configured even if you only have one CAS or a single multi-role server.
4. A CAS array object should not be resolvable via DNS by external clients
As mentioned in Part 1 (at least twice, I stopped counting) your CAS array object FQDN should not be the same FQDN used for other services such as OWA, ECP, EWS, EAS, Autodiscover, or the Outlook Anywhere external hostname.
The primary reason for this is Outlook Anywhere clients will first attempt to resolve the CAS array object FQDN via DNS so it knows if it should even bother to attempt a RPC (over TCP) connection or go right to HTTPS. Do you allow RPC (over TCP) connections directly in from the Internet to your Intranet? I hope you don’t, and if you do you’ll be getting a big red flag on your Exchange Risk and Health Assessment Program report. If the client does first attempt to connect via RPC (over TCP) due to being able to successfully resolve the CAS array object FQDN there could be a significant delay before the client falls back to attempt an HTTPS connection to the Outlook Anywhere proxy URL. This delay may result in higher helpdesk call generation if end users perceive this delay as degraded performance and/or the service being broken.
To avoid this situation simply make sure your internal CAS array object FQDN is something unique to internal DNS, perhaps like outlook.corp.contoso.com while your other non-RPC (over TCP) service URLs utilize something like mail.contoso.com internally and externally via split DNS.
If you haven't had the opportunity to utilize split DNS, it is when you have a set of internal AND external DNS servers handling requests for the same forward lookup zone, for example contoso.com. The two DNS infrastructures are completely isolated from each other. There are no zone transfers, nor are they utilizing each other as DNS forwarders. This configuration allows internal users utilizing the internal DNS infrastructure to resolve the host mail.contoso.com to an internal IP address (for example, 192.168.1.10) that goes to your load balancer VIP while external users resolve it to the public IP address which may point to your Internet-facing Forefront TMG/UAG infrastructure in your perimeter network. It's very common for the CAS array object IP address and the internal IP address of the non-RPC (over TCP) service URLs (OWA, ECP, EWS, etc…) to be the same load balancer VIP, but they may utilize different is-alive checks for proper service state detection.
Does your DNS serve a wildcard response?
I've had at least one customer who had an external DNS server that utilized a wildcard record in response for any query it received for a non-existent hostname. This meant you could send a DNS request for SomeFunkyNameThatDoesNotExist.contoso.com and the DNS server would always return the IP address of their corporate web site. (Wildcard records are completely valid from an Internet standards viewpoint. See section 4.3.3 in RFC 1034 for details -Editor).
Because of this their Outlook Anywhere clients could always resolve the CAS array object FQDN and would first attempt a RPC (over TCP) connection before switching to HTTPS. If you find yourself in a similar situation with an external DNS server utilizing a wildcard responses for a particular forward lookup zone, I'd recommend trying to avoid using that forward lookup zone for your Outlook Anywhere proxy URL.
A quick detour if we may to remind you not to forget to configure the proper service health monitors for your load balancing solution. For the best service monitoring results consult with your load balancing solution vendor. Check out Exchange Server 2010 Load Balancer Deployment for a list of the load-balancer vendors who've gone through Exchange 2010 solution testing and links to their relevant web pages (for Exchange 2010). Note, it's *not* a definitive list of supported load balancing vendors in any way. It's simply a list of vendors who've chosen to engage with Microsoft directly for solution testing and support.
A quick and dirty example may be that your HTTPS service based FQDNs have is-alive tests performed against TCP/443 responses and the load balancing solution stops sending new client traffic to any Client Access server which stops responding on TCP/443. The CAS array object RPC (over TCP) service FQDN may have is-alive tests performed on the RPC Endpoint Mapper on TCP/135 as well as the two static TCP ports you chose for RPC Client Access Service and the Address Book service. If any of those three ports stop responding on a particular Client Access server, the load balancing solution will not send new client traffic to that CAS for RPC (over TCP) until all of ports begin responding once again. If you don't configure static TCP ports then Exchange will choose a dynamic TCP port for each service at startup making is-alive testing more difficult if not impossible for some load balancing solutions.
5. A CAS array object should not be configured after creating Exchange Server 2010 databases
Many times we're all in a rush to install the Mailbox servers, have the mailbox databases created, and hopefully begin storage solution validation testing with Jetstress. May I suggest you slow your horses down for a moment and save yourself some trouble later? While Mailbox servers are considered by many to be the most important server role, it's no good to you if the front door is nailed shut because you can’t get to them through Client Access servers.
If you start creating mailbox databases before a CAS array object is in place you'll see a random Client Access server in the same Active Directory site stamped on the RpcClientAccessServer attribute of the each database.
Instead of looking like it should (use the CAS array object's FQDN)

Figure 1: If a CAS array object is created, the RpcClientAccessServer property of the mailbox database is populated with the CAS array object's FQDN
It will look something like this:

Figure 2: If the CAS array object is not created, the RpcClientAccessServer property of the mailbox database is populated with the Client Access server FQDN
Client profiles will look like the following…
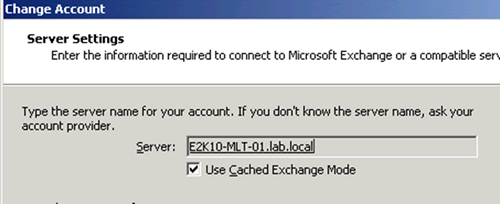
Figure 3: If a CAS array object is not created, Outlook clients are configured with the Client Access server's fqdn
Clients will connect like the following…
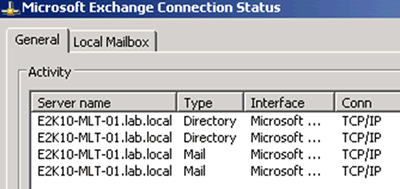
Figure 4: Clients connect to the Client Access server's fqdn
At first glance this may seem very innocuous and everything will work just fine, but you are setting yourself up for trouble later. If you start to move mailboxes to Exchange Server 2010 with this configuration in place Outlook will use the CAS name in the “Server” field of the user profile. It'll work, unless that Client Access server becomes unavailable or is perhaps decommissioned at a later date and replaced with a differently named server. Wouldn’t you rather be using a load-balanced pool of Client Access servers about the time that happens? ? Yes, you would!
You may think to yourself “Ok smarty pants, if that day ever comes I’ll create a CAS array object and fix RpcClientAccessServer on the databases and life will be good.” I’m here to tell you that will only work for mailboxes you move to Exchange 2010 after the fact. Any user with a pre-existing Outlook profile configured to point to a CAS name and not the CAS array object will continue to connect to the CAS name and it will not update itself to utilize the CAS array object FQDN.
The profile will not update itself because the client will not receive an ecWrongServer response from CAS. It will not receive this response because any CAS is a valid connection point for any mailbox database via RPC (over TCP) so clients can survive datacenter switchover/failover events without being reconfigured and all an admin has to do is flip the CAS array object DNS record to point to a surviving pool of CAS. Currently the only way to fix mailbox profiles would be a manual profile repair within Outlook, by publishing an Office PRF file via GPO (not going to work for non-domain joined machines), or by decommissioning the CAS server named in the users’ profiles so the endpoint is no longer available. This last option should (test test test!!) trigger a full profile repair by Autodiscover in Outlook 2007 or Outlook 2010. Outlook 2003 is only repairable with a profile repair or a PRF file. Autodiscover will not as of this article’s writing update a profile to a new server name as part of the normal Autodiscover process which updates the Outlook Anywhere configuration and discovers EWS URLs for other features such as OOF Management, Free/Busy, and Inbox Rules management.
This also means if you move a mailbox from a database in an AD Site-A that uses a CAS array object named Boston-CASArray to a database in AD Site-B which uses a CAS array object named Redmond-CASArray that the profile will not update and the server name field will remain the Boston-CASArray FQDN is. You may want to keep this in mind if you have a user population that migrates to different sites due to job changes or perform a massive internal mailbox move to another site at some time during the solution lifecycle. If you do find yourself creating Exchange 2010 databases before creating a CAS array object it is imperative that you go back and fix the databases’ RpcClientAccessServer attribute to use the CAS array object before moving mailboxes into the databases.
6. A CAS array object should be configured even if you only have one CAS server or one multi-role server.
Reflect for a moment about what was discussed in the prior item. A client will not update itself to use a CAS array object if you add one at a later time. Well what if you only have one CAS? You may think it doesn’t matter. I guess one could argue it doesn’t matter at that very moment, but why not future proof things if you can and save some cycles and frustration later? What if a year from now you find yourself in need of replacing that CAS? If you’re clients profiles are all pointing to a CAS name then you have no clean way to transition them without some kind of outage or manual work. You will have to repair their profiles with one of the means already mentioned after adding a new CAS, or you will have to decommission the existing CAS and introduce a new CAS with the same hostname which will require some downtime. To me none of those options are acceptable.
What if later on your business requirements change and then dictate you should have client access high availability? You can only achieve this goal by adding a second CAS and a load balancing solution. You will find yourself stuck in the same boat again having to repair everyone’s profile through one of the means already discussed. Again these are not acceptable options to me.
What I would suggest is you create a CAS array object from the very beginning. How do you do that if you have no load balancer and only a single CAS? Simple! Configure the CAS array object like you normally would. Give it a name, an AD site, a FQDN, and then simply point the DNS ‘A’ record to the IP as the only existing CAS or multi-role server you have at that time. You have just future-proofed yourself and if you ever have to replace the single CAS or multi-role server all you have to do is build the new server, and then change the DNS record IP address and everything keeps working without interruption. If you ever want to add high availability at a later time then all you have to do is get your load balancing solution operational and then change the CAS array object DNS record IP address to point at the VIP of the load balancing solution. Easy!
Hopefully this article has been helpful in addressing some of the CAS array object misconceptions and will go a long ways towards helping everyone move towards a healthy Exchange Server 2010 migration.
Brian Day Premier Field Engineer, Messaging
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.